오픈소스 리뷰 : 슬기로운 오픈소스 사용법 리뷰해드립니다!
#14 문서 추출 요약 모델 "KoBART_summarization"

안녕하세요. 디노랩스입니다!
KoBART는 SKT 에서 공개한 한국어 BART모델로 사전학습된 모델을 누구나 사용할 수 있도록 배포되었습니다.
이를 활용하여 챗봇, 번역, 기사요약 등 다양한 분야에서 finetuning 된 모델이 만들어지고 있고 사전학습된 모델 역시 누구나 간단한 코드 작성을 통해 사용할 수 있습니다.
이번 시간에는 사전학습된 KoBART를 활용햐여 학습된 뉴스 기사 요약 모델을 가져와 사용하는 방법을 알아보겠습니다.
https://github.com/SKT-AI/KoBART
GitHub - SKT-AI/KoBART: Korean BART
Korean BART. Contribute to SKT-AI/KoBART development by creating an account on GitHub.
github.com
01. ainize/kobart-news
KoBART 모델을 활용하여 만들어진 뉴스기사 요약 모델 중 huggingface에 배포된 모델을 먼저 살펴보겠습니다.
https://huggingface.co/ainize/kobart-news
ainize/kobart-news · Hugging Face
New Select AutoNLP in the “Train” menu to fine-tune this model automatically.
huggingface.co
# 먼저 huggingface의 transforemers 라이브러리를 설치합니다.
!pip install transformers
# 모델과 문장 분리를 위한 토크나이저를 불러옵니다.
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained("ainize/kobart-news")
model = BartForConditionalGeneration.from_pretrained("ainize/kobart-news")
위와 같이 간단한 코드 몇줄로 모델과 토크나이저를 불러올 수 있습니다.
이제 이를 활용하여 뉴스기사를 직접 요약해보겠습니다.
# 요약하고자 하는 기사를 입력합니다.
# 기사원문: http://news.heraldcorp.com/view.php?ud=20211127000015
news_text = "세계가 ‘오미크론(Omicron)’ 공포에 빠졌다. 코로나19 델타변이도 잡지 못해 전전긍긍하는데 세계보건기구(WHO)가 또 다른 ‘우려 변이(variant of concern)’로 오미크론을 지정하면서다. 항체를 무력화 수 있는 돌연변이가 많은 걸로 파악되는 오미크론이 코로나19 백신엔 어떤 영향을 미칠지를 보려면 추가 연구가 필요한 상황이다. 각 국은 서둘러 국경의 빗장을 걸고 있다. 미국과 유럽 등 글로벌 증시를 폭락시킨 오미크론은 현재로선 어디로 튈지 모르는 변이여서 두려움을 더하고 있다."
# 토크나이저를 사용하여 뉴스기사 원문을 모델이 인식할 수 있는 토큰형태로 바꿔줍니다.
input_ids = tokenizer.encode(news_text, return_tensors="pt")
# input_ids 를 확인해보면 아래와 같이 텍스트가 토큰 단위로 쪼개어진 뒤 모두 id형태의 숫자로 바뀐 것을 확인할 수 있습니다.
# "0": 문장 시작을 나타내는 토큰 id, "1": 문장 끝을 나타내는 토큰 id
print(input_ids)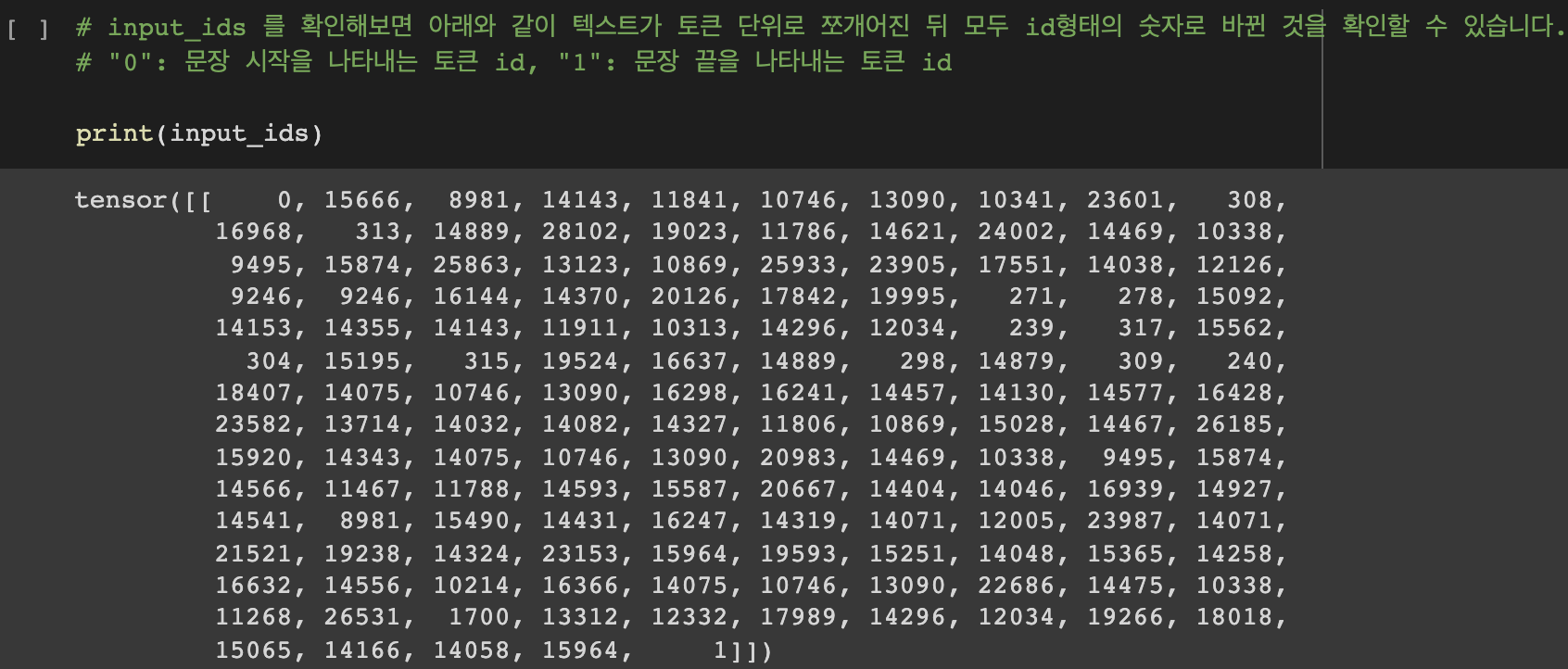
이제 숫자로 변환된 뉴스기사를 모델의 input으로 사용하여 생성된 요약문을 확인해보겠습니
summary_text_ids = model.generate(
input_ids=input_ids,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=2.0, # 길이에 대한 penalty. 1보다 작은 경우 더 짧은 문장을 생성하도록 유도하며, 1보다 클 경우 길이가 더 긴 문장을 유도
max_length=128, # 요약문의 최대 길이 설정
min_length=32, # 요약문의 최소 길이 설정
num_beams=4, # 문장 생성시 다음 단어를 탐색하는 영역의 개수
)
print(summary_text_ids)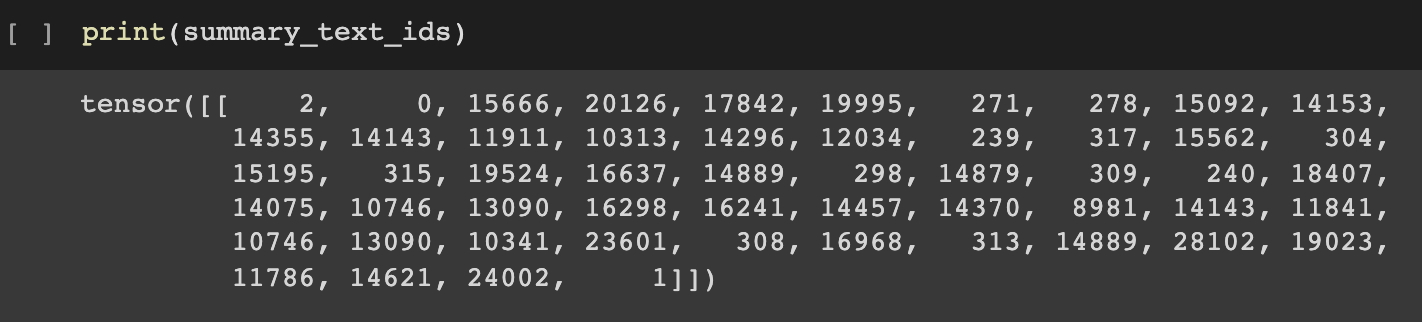
요약된 결과를 확인해보면 모두 id 형태로 이루어진 것을 확인할 수 있습니다.
토크나이저를 사용하여 이를 텍스트 형태로 바꿔보겠습니다.
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))
위와 같이 KoBART 를 활용하여 만들어진 뉴스기사 요약모델이 문장의 핵심을 잘 파악하여 요약문을 생성하는 것을 확인할 수 있습니다.
02. gogamza/kobart-summarization
이번에는 다른 데이터로 학습된 요약모델을 사용해보겠습니다.
이 모델 역시 huggingface에 배포되어 있으며 이전 모델과 마찬가지로 간단한 코드로 불러올 수 있습니다.
# 모델과 문장 분리를 위한 토크나이저를 불러옵니다.
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained("gogamza/kobart-summarization")
model = BartForConditionalGeneration.from_pretrained("gogamza/kobart-summarization")
# 요약하고자 하는 기사를 입력합니다.
# 기사원문: http://news.heraldcorp.com/view.php?ud=20211127000015
news_text = "세계가 ‘오미크론(Omicron)’ 공포에 빠졌다. 코로나19 델타변이도 잡지 못해 전전긍긍하는데 세계보건기구(WHO)가 또 다른 ‘우려 변이(variant of concern)’로 오미크론을 지정하면서다. 항체를 무력화 수 있는 돌연변이가 많은 걸로 파악되는 오미크론이 코로나19 백신엔 어떤 영향을 미칠지를 보려면 추가 연구가 필요한 상황이다. 각 국은 서둘러 국경의 빗장을 걸고 있다. 미국과 유럽 등 글로벌 증시를 폭락시킨 오미크론은 현재로선 어디로 튈지 모르는 변이여서 두려움을 더하고 있다."
# 토크나이저를 사용하여 뉴스기사 원문을 모델이 인식할 수 있는 토큰형태로 바꿔줍니다.
input_ids = tokenizer.encode(news_text)
print(input_ids)
# 모델에 넣기 전 문장의 시작과 끝을 나타내는 토큰을 추가합니다.
input_ids = [tokenizer.bos_token_id] + input_ids + [tokenizer.eos_token_id]
input_ids = torch.tensor([input_ids])
input_ids
이제 숫자로 변환된 뉴스기사를 모델의 input으로 사용하여 생성된 요약문을 확인해보겠습니다.
summary_text_ids = model.generate(
input_ids=input_ids,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=2.0, # 길이에 대한 penalty값. 1보다 작은 경우 더 짧은 문장을 생성하도록 유도하며, 1보다 클 경우 길이가 더 긴 문장을 유도
max_length=128, # 요약문의 최대 길이 설정
min_length=32, # 요약문의 최소 길이 설정
num_beams=4, # 문장 생성시 다음 단어를 탐색하는 영역의 개수
)
print(summary_text_ids)
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))
이전 모델에 비해 문장이 더욱 길어지면서 요약된 문장의 결과가 썩 좋지않은 것을 확인할 수 있습니다.
이번에는 요약문을 생성할 때 사용되는 파라미터를 조정하여 다시 요약문을 생성해보겠습니다.
summary_text_ids = model.generate(
input_ids=input_ids,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=1.0, # 길이에 대한 penalty값. 1보다 작은 경우 더 짧은 문장을 생성하도록 유도하며, 1보다 클 경우 길이가 더 긴 문장을 유도
max_length=128, # 요약문의 최대 길이 설정
min_length=32, # 요약문의 최소 길이 설정
num_beams=4, # 문장 생성시 다음 단어를 탐색하는 영역의 개수
)
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))
length_penalty 값을 2.0 에서 1.0 으로 줄인 결과 조금 더 그럴듯한 요약문을 생성하는 것을 확인할 수 있습니다.

문서 추출 요약 모델 "KoBART_summarization"어떠셨나요?
잘 이용한다면 정말 간편할 것 같죠? ㅎㅎ
오늘의 오픈소스 리뷰기 여기까지입니다 :)

'BLOG > 오픈소스 리뷰기' 카테고리의 다른 글
| [오픈소스 리뷰기] Pororo 자연어처리 라이브러리(2)Sequence Tagging (0) | 2021.12.15 |
|---|---|
| [오픈소스 리뷰기] Pororo 자연어처리 라이브러리(1)Text Classification (0) | 2021.12.14 |
| [오픈소스 리뷰기] TTS(Text-to-Speech) 음성합성기술 API 이용하기 (1) | 2021.11.24 |
| [오픈소스 리뷰기] 나만의 텔레그램 챗봇 만들기! (0) | 2021.11.19 |
| [오픈소스 리뷰기] 네이버 검색광고 API 이용하기 (5) | 2021.11.17 |



