오픈소스 리뷰 : 슬기로운 오픈소스 사용법 리뷰해드립니다!
#11 네이버 검색광고 API 이용하기

안녕하세요. 디노랩스입니다!
지난 시간에 이어 이번 시간에는 네이버에서 제공하는 검색광고 API 활용법을 알아볼건데요.
데이터랩 API에서 제공했던 통합 검색어 트렌드, 쇼핑인사이트와는 다르게 검색광고 API에서는 키워드도구라는 기능을 제공합니다. 키워드도구를 사용하여 키워드 검색량을 조회할 수 있고 연관키워드들을 추출할 수 있는데, 이를 활용한다면 마케터 혹은 기획자들이 현업에서 요긴하게 사용될 거에요! >_<

키워드도구 기능 역시 네이버 검색광고(LINK)에서 제공하고 있습니다. 하지만 검색광고 API를 활용하면 직접 데이터를 수집하여 사용 목적에 알맞게 데이터를 가공할 수 있으며 반복 작업이 필요한 경우 조금 더 효율적으로 데이터를 수집할 수 있다는 장점이 있습니다.
이번 실습에서 작성한 코드를 활용하여 업무의 효율성을 높여보세요!!😀
네이버 광고
searchad.naver.com
01_API 이용신청
검색광고 API 역시 활용하기 위해서는 API 이용 신청을 해야합니다. 아래 링크에 접속하여 로그인한 뒤 우측상단의 광고시스템 > 도구 > API 사용관리 > 네이버 검색광고 API 서비스 신청 버튼을 눌러 이용신청을 완료해주세요!
네이버 광고
searchad.naver.com


신청이 완료되었다면 내 계정, 엑세스라이선스, 비밀키 를 확인할 수 있습니다.

02_연관키워드 및 검색량조회
키워드, 업종, 시즌 월, 시즌 테마를 입력하여 연관 키워드 및 검색량 등을 조회해보겠습니다.
우선 필요한 라이브러리를 import 하고 생성한 key 들을 입력합니다.
import time
import random
import requests
import hashlib, hmac, base64
# 생성된 key를 변수에 저장합니다.
CUSTOMER_ID = 'CUSTOMER_ID 를 입력하세요'
API_KEY = '엑세스라이선스 를 입력하세요'
SECRET_KEY = '비밀키 를 입력하세요'
먼저 네이버 github에서 제공하는 sample code를 참고하여 API사용에 필요한 모듈과 함수를 정의하겠습니다.
[참고] https://github.com/naver/searchad-apidoc/tree/master/python-sample/examples
GitHub - naver/searchad-apidoc
Contribute to naver/searchad-apidoc development by creating an account on GitHub.
github.com
def generate(timestamp, method, uri, secret_key):
message = "{}.{}.{}".format(timestamp, method, uri)
hash = hmac.new(secret_key.encode("utf-8"), message.encode("utf-8"), hashlib.sha256)
hash.hexdigest()
return base64.b64encode(hash.digest())
def get_header(method, uri, api_key, secret_key, customer_id):
timestamp = str(int(time.time() * 1000))
signature = generate(timestamp, method, uri, SECRET_KEY)
return {'Content-Type': 'application/json; charset=UTF-8', 'X-Timestamp': timestamp, 'X-API-KEY': API_KEY, 'X-Customer': str(CUSTOMER_ID), 'X-Signature': signature}
다음으로 키워드 도구 API를 사용하기 위해 네이버 검색광고 API Document의 RelKwdStat 서비스를 살펴보겠습니다.
http://naver.github.io/searchad-apidoc/#/operations/GET/~2Fkeywordstool
searchad-apidoc
naver.github.io

위 사진을 보면 API에 요청할 때 사용되는 method 는 GET 방식이며 URI는 /keywordstool 임을 확인할 수 있습니다.
또한 Parmater 항목을 통해 요청식 입력하는 parameter들을 확인할 수 있습니다.
- siteId : 웹사이트 ID
- biztpId : 업종 ID
- hintKeywords : 키워드 (최대 5개)
- event : 시즌 테마
- 테마별 코드 참고
- month : 시즌 월
- showDetail : 검색결과에 검색량,CTR 등의 지표들을 포함할지 여부를 결정
- 1 : 관련 키워드, 검색량, CTR, 경쟁정도 등을 모두 표시
- 0 : 관련 키워드, 월간 검색수 만 표시
요청에 사용되는 parameter 들은 아래 사진과 같이 실제 키워드 도구 페이지에서 확인할 수 있습니다.

이제 uri 와 parameter 들을 모두 확인했으니 키워드를 입력해보겠습니다.
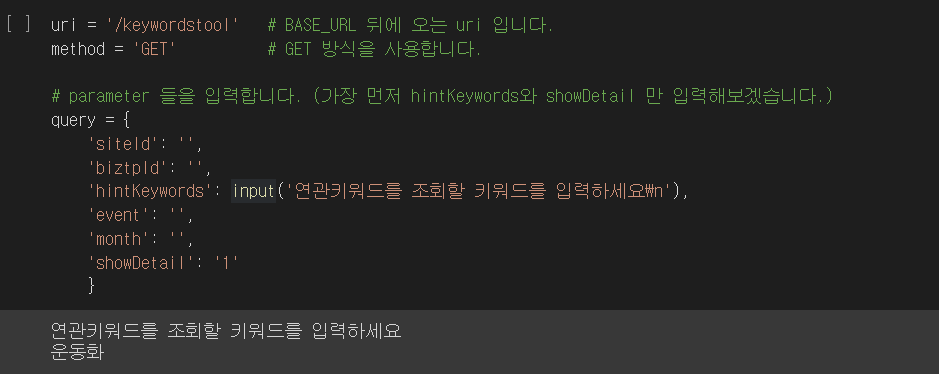
uri = '/keywordstool' # BASE_URL 뒤에 오는 uri 입니다.
method = 'GET' # GET 방식을 사용합니다.
# parameter 들을 입력합니다. (가장 먼저 hintKeywords와 showDetail 만 입력해보겠습니다.)
query = {
'siteId': '',
'biztpId': '',
'hintKeywords': input('연관키워드를 조회할 키워드를 입력하세요\n'),
'event': '',
'month': '',
'showDetail': '1'
}
이제 BASE_URL과 uri, query 들을 합쳐 API에 request 해보겠습니다.
BASE_URL = 'https://api.naver.com'
r = requests.get(
BASE_URL + uri,
params = query,
headers = get_header(
method=method,
uri=uri,
api_key=API_KEY,
secret_key=SECRET_KEY,
customer_id=CUSTOMER_ID
))
r_data = r.json()
return 된 결과를 확인해보겠습니다.
r_data.keys()
len(r_data['keywordList'])
r_data['keywordList'][0]
위와 같이 호출한 데이터를 확인해보면 'relKeyword'라는 키의 값에 '운동화'가 출력된 것을 확인할 수 있으며, 검색된 키워드에 대한 여러 지표들이 함께 출력된 것을 확인할 수 있습니다.
- relKeyword : 연관키워드
- 선택한 기준과 연관도가 높은 키워드입니다.
- monthlyPcQcCnt : 월간검색수_PC
- monthlyMobileQcCnt : 월간검색수_모바일
- 최근 한 달 간 사용자가 해당 키워드를 검색했을 때, 통합검색 영역에 노출된 광고가 받은 평균 클릭수 입니다
- monthlyAvePcClkCnt : 월평균클릭수_PC
- monthlyAveMobileClkCnt : 월평균클릭수_모바일
- 최근 한 달 간 사용자가 해당 키워드를 검색했을 때, 통합검색 영역에 노출된 광고가 받은 평균 클릭수 입니다.
- monthlyAveMobileCtr : 월평균클릭률_모바일
- monthlyAvePcCtr : 월평균클릭률_PC
- 최근 한 달간 해당 키워드로 통합검색 영역에 노출된 광고가 받은 평균 클릭률을 의미합니다.
- 클릭률의 의미: 광고가 노출되었을때 노출된 광고가 검색사용자로부터 클릭을 받는 비율을 말합니다.
- compIdx : 경쟁정도
- 최근 한달간 해당 키워드에 대한 경쟁정도를 PC통합검색영역 기준으로 높음/중간/낮음으로 구분한 지표입니다. 다수의 광고주가 추가한 광고일수록 경쟁정도는 높을 수 있습니다.
- plAvgDepth : 월평균노출광고수
- 최근 한 달 간 사용자가 해당 키워드를 검색했을 때, PC통합검색 영역에 노출된 평균 광고 개수입니다. "경쟁정도"지표와 함께 키워드의 경쟁정도를 가늠해볼 수 있습니다.
실제 네이버 검색광고 키워드 도구에서 '운동화'를 검색한 결과와 API를 통해 호출한 데이터를 비교해보세요.

이제 호출한 데이터를 pandas를 사용하여 데이터 프레임 형태로 변환해보겠습니다.
import pandas as pd
# 데이터프레임을 생성합니다.
df = pd.DataFrame(r.json()['keywordList'])
# 칼럼명을 변경합니다.
df.rename({
'compIdx':'경쟁정도',
'monthlyAveMobileClkCnt':'월평균클릭수_모바일',
'monthlyAveMobileCtr':'월평균클릭률_모바일',
'monthlyAvePcClkCnt':'월평균클릭수_PC',
'monthlyAvePcCtr':'월평균클릭률_PC',
'monthlyMobileQcCnt':'월간검색수_모바일',
'monthlyPcQcCnt': '월간검색수_PC',
'plAvgDepth':'월평균노출광고수',
'relKeyword':'연관키워드'
},
axis=1,
inplace=True)
# 10건 미만인 데이터의 경우 특수기호('<')를 포함합니다.
# 손쉬운 데이터 처리를 위해 특수기호 ('<') 를 제거합니다.
df = df.replace('< 10','10')
# 데이터 타입을 변경합니다.
df[['월간검색수_PC', '월간검색수_모바일']] = df[['월간검색수_PC', '월간검색수_모바일']].apply(pd.to_numeric)
df.head()
df.info()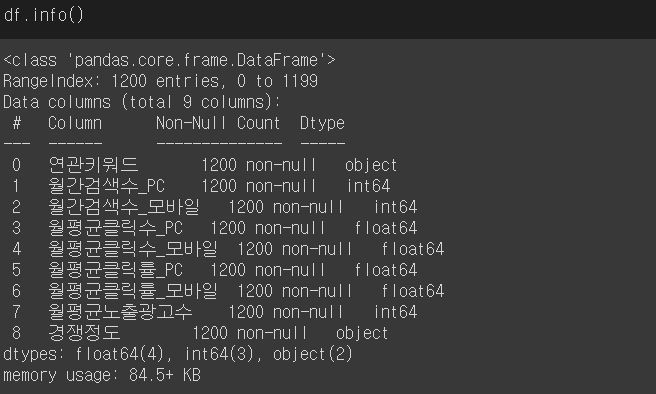
# sort_values() 메서드를 활용하여 월간검색수_PC를 기준으로 높은순서대로 확인할 수 있습니다.
df.sort_values(by='월간검색수_PC', ascending=False)
03_클래스로 구현
# colab에서 한글 폰트 사용을 하기 위한 코드
import matplotlib.font_manager as fm
!apt-get -qq -y install fonts-nanum > /dev/null
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
fm._rebuild()
# 한글 폰트 사용을 위해 런타임을 재시작합니다.
import os
os.kill(os.getpid(), 9)
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.font_manager as fm
# 마이너스 표시 문제
mpl.rcParams['axes.unicode_minus'] = False
# 한글 폰트 설정
path = '/usr/share/fonts/truetype/nanum/NanumGothicBold.ttf'
font_name = fm.FontProperties(fname=path, size=18).get_name()
plt.rc('font', family=font_name)
fm._rebuild()
import time
import random
import requests
import hashlib, hmac, base64
import pandas as pd
from wordcloud import WordCloud
class NaverSearchadKeywordAPI():
"""
네이버 검색광고 키워드 오픈 API 컨트롤러 클래스
"""
def __init__(self, customer_id, api_key, secret_key):
"""
인증키 설정 및 base url 초기화
"""
self.customer_id = customer_id
self.api_key = api_key
self.secret_key = secret_key
self.base_url = "https://api.naver.com"
def _generate(self, timestamp, method, uri, secret_key):
"""
signature를 generate 하는 함수
"""
message = "{}.{}.{}".format(timestamp, method, uri)
hash = hmac.new(secret_key.encode("utf-8"), message.encode("utf-8"), hashlib.sha256)
hash.hexdigest()
return base64.b64encode(hash.digest())
def _get_header(self, method, uri, api_key, secret_key, customer_id):
"""
header 생성 함수
"""
timestamp = str(int(time.time() * 1000))
signature = generate(timestamp, method, uri, secret_key)
return {'Content-Type': 'application/json; charset=UTF-8', 'X-Timestamp': timestamp, 'X-API-KEY': API_KEY, 'X-Customer': str(customer_id), 'X-Signature': signature}
def get_data(self,
hintKeywords=None,
siteId=None,
biztId=None,
event=None,
month=None,
showDetail=1):
"""
요청 결과 반환
"""
# keyword를 입력하지 않을 경우 에러를 발생시킵니다.
assert hintKeywords != None, "keyword를 입력하세요!!"
query = {
'siteId': siteId,
'biztpId': biztId,
'hintKeywords': hintKeywords,
'event': event,
'month': month,
'showDetail': showDetail,
}
r = requests.get(
self.base_url + uri,
params = query,
headers = self._get_header(
method='GET',
uri='/keywordstool',
api_key=self.api_key,
secret_key=self.secret_key,
customer_id=self.customer_id,
))
self.df = pd.DataFrame(r.json()['keywordList'])
# 칼럼명을 변경합니다.
self.df.rename({
'compIdx':'경쟁정도',
'monthlyAveMobileClkCnt':'월평균클릭수_모바일',
'monthlyAveMobileCtr':'월평균클릭률_모바일',
'monthlyAvePcClkCnt':'월평균클릭수_PC',
'monthlyAvePcCtr':'월평균클릭률_PC',
'monthlyMobileQcCnt':'월간검색수_모바일',
'monthlyPcQcCnt': '월간검색수_PC',
'plAvgDepth':'월평균노출광고수',
'relKeyword':'연관키워드'
},
axis=1,
inplace=True)
# 10건 미만인 데이터의 경우 특수기호('<')를 포함합니다.
# 손쉬운 데이터 처리를 위해 특수기호 ('<') 를 제거합니다.
self.df = self.df.replace('< 10','10')
# 데이터 타입을 변경합니다.
self.df[['월간검색수_PC', '월간검색수_모바일']] = self.df[['월간검색수_PC', '월간검색수_모바일']].apply(pd.to_numeric)
return self.df
def plot_wordcloud(self, by, topk):
"""
상위 k개의 연관검색어를 워드클라우드로 시각화하는 함수
"""
assert by in {"월간검색수_PC", "월간검색수_PC", "월간검색수_모바일", "월평균클릭수_PC", "월평균클릭수_모바일", "월평균클릭률_PC", "월평균클릭률_모바일", "월평균노출광고수"}, "정렬기준을 정확하게 입력하세요"
# 정렬된 데이터를 topk 개 만큼만 불러옵니다.
topk_df = self.df.sort_values(by=by, ascending=False).loc[:topk,["연관키워드",by]]
# 연관키워드를 key로, 데이터를 value로 하는 딕셔너리를 생성합니다.
keywords = topk_df.set_index('연관키워드').to_dict()[by]
# WordCloud 객체를 생성합니다.
wc = WordCloud(
font_path='/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf', # 한글 설정을 위해 폰트 경로를 지정합니다. ()
background_color="white",
width=2000,
height=1000,
)
# keywords 딕셔너리로부터 이미지를 생성합니다.
cloud = wc.generate_from_frequencies(keywords)
plt.figure(figsize=(20,10))
plt.title(f"{by} 기준 상위 {topk} 개 연관검색어", fontsize=20)
plt.axis('off')
plt.imshow(cloud)
return cloud
# apple 이라는 인스턴스를 생성해보겠습니다.
apple = NaverSearchadKeywordAPI(
customer_id='CUSTOMER_ID 를 입력하세요',
api_key='엑세스라이선스 를 입력하세요',
secret_key='비밀키 를 입력하세요'
)
# 키워드로 "애플"을 입력하여 데이터를 로드합니다.
apple.get_data(hintKeywords='애플')
# "월간검색수_모바일"을 기준으로 상위 30개의 연관검색어를 시각화해보겠습니다.
apple.plot_wordcloud(by="월간검색수_모바일", topk=30)
오늘은 여기까지 입니다!!
네이버에서 제공하는 데이터랩, 쇼핑인사이트에 이어서 오늘 검색광고 API 이용하는 법까지 함께 해보았는데요.
정말 여러 방면에서 활용적일것 같죠? ㅎㅎ
슬기로운 오픈소스 사용법! 남은 포스팅들도 기대해주세요!

'BLOG > 오픈소스 리뷰기' 카테고리의 다른 글
| [오픈소스 리뷰기] TTS(Text-to-Speech) 음성합성기술 API 이용하기 (1) | 2021.11.24 |
|---|---|
| [오픈소스 리뷰기] 나만의 텔레그램 챗봇 만들기! (0) | 2021.11.19 |
| [오픈소스 리뷰기] 네이버 데이터랩(2) - 쇼핑 인사이트 (1) | 2021.11.16 |
| [오픈소스 리뷰기] 네이버 데이터랩(1) - 통합 검색어 트렌드 (1) | 2021.11.15 |
| [오픈소스 리뷰기] DART 전자공시시스템(2) - DART-FSS라이브러리 활용하기! (0) | 2021.11.12 |



