에어 프로젝트
#4 TextRank로 크롤링한 뉴스 기사 요약 모델 만들기

현재 온라인의 주요 플랫폼에서는 여러 분야의 다양한 정보들을 뉴스기사, 포스팅, 영상 등 다양한 형태로 제공하고 있다.
예를 들어, 금융 분야에 관심이 많아 평소에 뉴스 기사를 찾아서 읽는다고 한다면, 기사를 제공하는 플랫폼에 들어가서 '금융' 카테고리를 눌러 기사를 확인할 것이다. 하지만 매일 올라오는 기사는 한 분야에서도 수백건으로, 일일이 다 확인하는 데에는 분명 적지 않은 시간이 소요될 것이다. 이렇게 온라인 상에서 정보가 흘러넘치는 시대라도, 바쁜 삶을 살아가는 현대인들에게는 이마저도 일이 될 수 있다.
따라서 이번 에어 프로젝트에서는 네이버에서 제공하는 '금융-가장 많이 본 뉴스' 페이지에서 원하는 날짜의 기사를 크롤링한 뒤, 텍스트를 요약해주는 TextRank 모델을 이용하여 뉴스 기사를 요약하는 모델을 만들고자 한다. 또한 요약 뿐만 아니라 뉴스 기사의 주요 키워드도 찾아보고자 한다.
그렇다면 텍스트 모델을 만들어 보기 전에, TextRank 모델에 대해 먼저 간단하게 알아보도록 하자!
|| 텍스트 요약이란?
TextRank에 대해 알아보기 앞서, 텍스트 요약에는 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)으로 나눠진다.
추출적 요약은 말 그대로 기존의 글에서 중요도가 높거나 핵심이 되는 문장을 그대로 추출해서 요약문을 만드는 것이다. 즉, 새로운 단어가 생겨나거나 새로운 문장이 생성되지 않는 요약 방법을 말한다. 이와 반대로, 추상적 요약이란 새로운 단어와 새로운 문장을 생성해서 요약을 하는 방법을 말한다.
추출적 요약과 추상적 요약에 대해 생각해보자면, 예를 들어 선생님이 학생한테 독후감 과제를 냈는데, 한 명은 중요하다고 생각되는 문장들을 토씨 하나 바꾸지 않고 그대로 적어왔고, 다른 한 명은 자기 나름대로 새로운 문장을 만들어서 요약을 해서 왔다고 할 때, 전자는 추출적 요약, 후자는 추상적 요약이 될 것이다. 다만 차이가 있다면 후자 학생에게 좀 더 높은 점수가 부여되지 않을까 싶다.
이렇듯 추상적 요약이 일반적으로 더 사람의 요약 방식과 비슷하고, 좀 더 퀄리티가 좋은 요약 방법이지 않을까 싶다.
|| TextRank(텍스트랭크)란?
텍스트 요약의 한 종류인 추출적 요약법에도 다양한 기계번역 모델이나 알고리즘이 있다. 하지만 추출적 요약법의 가장 대표적인 것이 바로 TextRank이다. 그렇다면 TextRank가 뭘까? TextRank는 2004년 발표된 알고리즘으로, 구글의 PageRank 논문(1998) - The PageRank Citation Ranking : Bringing Order to the Web을 기반으로 한 알고리즘이다.
1.PageRank
PageRank에 대해 간단하게 설명하자면, 하이퍼링크를 가지는 웹 페이지에 대해서 얼마나 참조가 됐는지, 또는 얼마나 유입이 되었는지 등으로 페이지의 Rank(순위)를 매기는 알고리즘을 말한다.
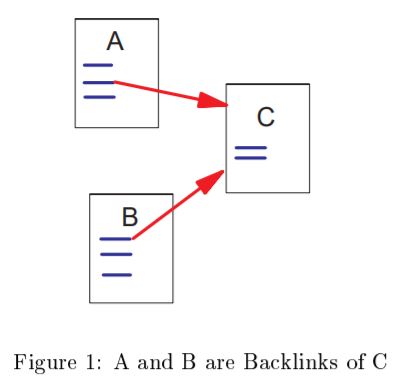
예를 들어, 인터넷 페이지에서 우연히 맘에 드는 상품이 광고로 떠서 해당 쇼핑몰 웹페이지를 클릭하고 들어갔을 때, 그 옷에 대해 살펴본 후 맘에 든다면 해당 쇼핑몰사이트에서 또 다른 상품을 보기 위해 상단에 Home화면으로 돌아가기 위한 배너 또는 버튼을 누를 것이다. 그리고 Home 화면에서 또 다른 카테고리를 눌러서 해당 페이지로 들어가고, 또 상단에 나와있는 베스트 상품 등을 보며 클릭해 상세 페이지로 들어가게 될 것이다. 그리고는 또 다시 Home화면이나 이전 페이지로 돌아가게 될 것이다. 이러한 경우, 가장 Rank가 높은 페이지는 어디가 될까? 바로 쇼핑몰 Home화면(Homepage)일 것이다. 그 다음 순위는 세부카테고리 페이지, 베스트 상품 페이지, 기타 다른 상품 페이지가 뒤를 이을 것이다.
이처럼 PageRank는 각 웹페이지마다 하이퍼링크가 있을 때, 얼마나 링크를 받느냐에 따라(유입이 되는지) 순위를 매기는 알고리즘을 말한다.추가로 덧붙이자면 PageRank에서는 링크를 클릭할 확률로 그 순위를 매긴다고 한다.
2.TextRank Model
다시 돌아와서, TextRank 모델은 이런 PageRank의 알고리즘을 활용한 것으로, 페이지의 개념을 단어의 개념으로 바꾼 알고리즘이다. 즉, 텍스트로 이루어진 글에서 특정 단어가 다른 문장과 얼마만큼의 관계를 맺고 있는지를 계산하는 것이다. TextRank 논문 TextRank : Bringing Order into Texts 에 따르면 TextRank는 그래프 기반의 랭킹 모델(graph-based ranking model)로, 이러한 순위를 매기는 방법이 문단의 추출적 요약에 매우 효과적일 것이라 생각되어 개발했다고 한다.
그렇다면 어떻게 순위를 매기냐가 관건인데, 논문에 따르면 'voting' 또는 'recommendation'과 같은 아이디어를 생각했다고 한다. 예를 들어, 한 vertex(=node)가 다른 vertex와 연결된다면 이를 연결한 vertex에 투표(casting a vote)했다고 본다. 이렇게 다른 vertex에 투표하는 수가 많아질수록, 특정 vertex의 중요도는 점점 커지게 되는 것이다. 그리고 이 투표 수는 그 vertex의 순이를 매기게 되는 값이 되는 것이다.

위 이미지는 상단에 주어진 글에 대해 텍스트 간 관계를 나타낸 그래프를 그린 샘플 이미지이다. 내용과 그래프를 비교해보면 각 문장에서 단어 간의 관계를 선으로 연결한 것을 살펴볼 수 있는데, 이때 순위는 다음과 같은 수식에 의해 매긴다고 한다.

위 식에서 S(Vi)가 최종적으로 구하려는 TextRank 값을 의미하고, Wji는 해당 문장이나 단어 i와 j 사이의 가중치를 의미한다. Wji를 정의하는 수식에 대해서는 TextRank 논문에 나와있는데, 곧 코드를 통해서 어떻게 구하는지 살펴보도록 하겠다. 한편, d는 damping facter로, 한 vertex에서 다른 vertex로 연결될 확률로 0과 1사이의 숫자를 갖는다(논문에서는 0.85로 지정). 이렇게 vertex마다 위 식을 통해 TextRank 값을 구하고 나면, 그 크기대로 정렬을 해서 순위를 매기게 된다.
한편, 논문에 따르면 자연어 텍스트에 대한 graph-based ranking 알고리즘은 다음과 같이 수행된다고 하니, 참고하면 좋을 것 같다.
1. Identify text units that best define the task at hand, and add them as vertices in the graph.
2. Identify relations that connect such text units, and use these relations to draw edges between vertices in the graph. Edges can be directed or undirected, weighted or unweighted.
3. Iterate the graph-based ranking algorithm until convergence.
4. Sort vertices based on their final score. Use the values attached to each vertex for ranking/selection decisions.
|| Project Description
이번 에어 프로젝트에 대해 설명하자면, TextRank 모델로 네이버의 금융 플랫폼에서 '가장 많이 본 뉴스' 카테고리에 있는 뉴스 기사들을 요약하는 모델 만들고자 한다. 따라서 TextRank 모델을 코드로 구현을 하여 뉴스 기사를 요약하고자 하는데, 모델을 만들기 전에 먼저 뉴스 기사들을 날짜에 따라 웹크롤링하는 코드부터 설명하도록 하겠다. (요약할 데이터를 가져오는 단계라 TextRank 모델 구현과는 관련없는 부분이다 => 생략가능) 코드는 juypter notebook에서 작성되었다.
[1] 데이터 수집 : [네이버-금융-가장 많이 본 뉴스] 기사 크롤링하기
우선, 웹크롤링을 할 페이지이다.
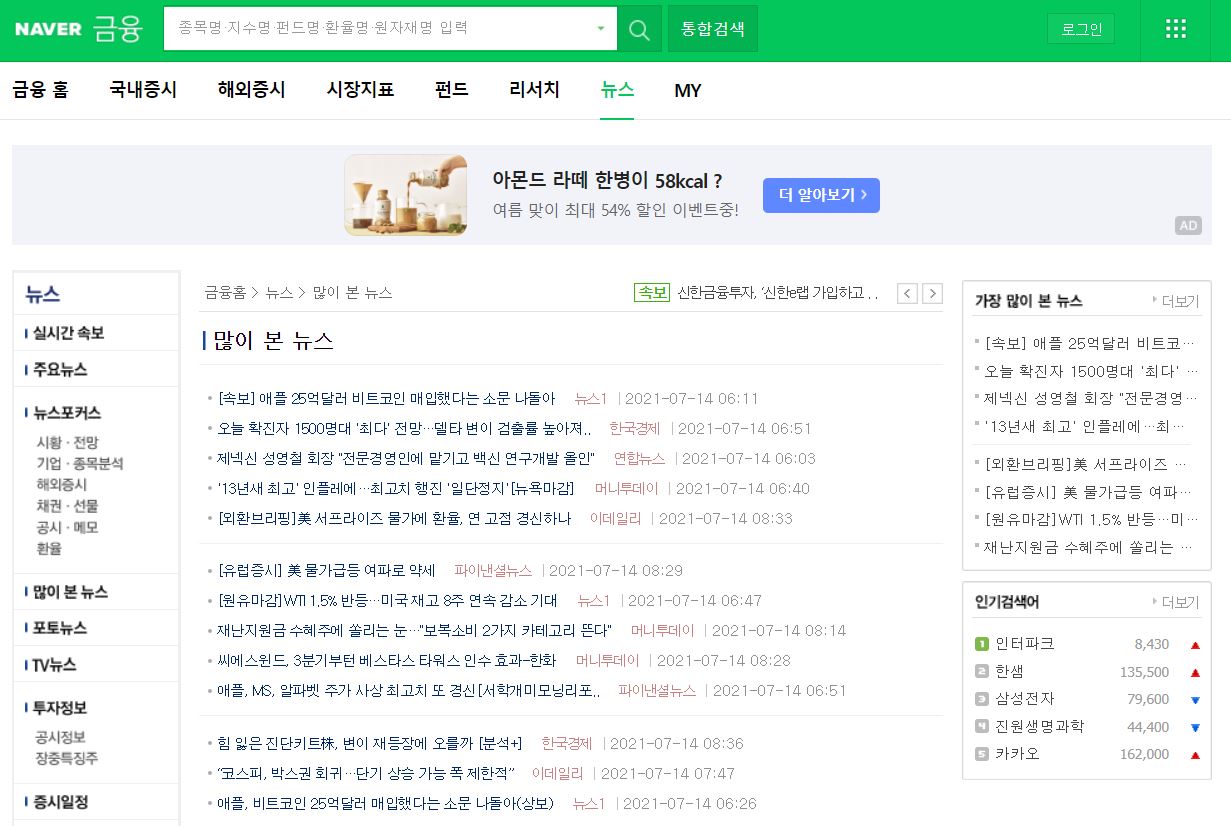
위 페이지는 [네이버]-[금융]-[뉴스]-[많이 본 뉴스]의 경로로 들어올 수 있고, 오른쪽 배너에 [가장 많이 본 뉴스] 옆에 '+더보기' 버튼을 통해 들어올 수 있는 페이지이다. 위 페이지에 들어가게 되면 <많이 본 뉴스>로 총 25개의 기사가 나오는데, 여기서 한 기사를 클릭하면 아래와 같이 기사가 있는 페이지로 들어가게 된다.
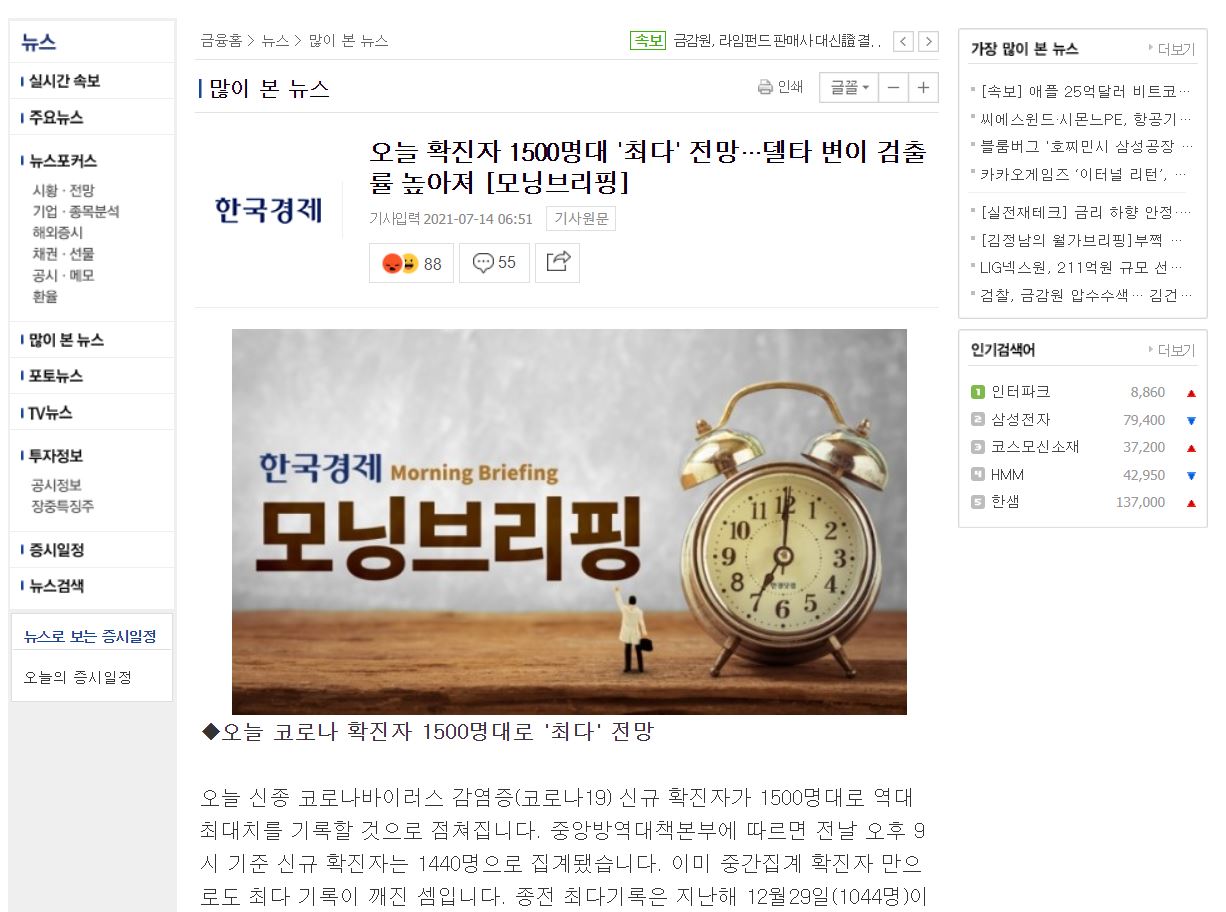
그리고 이 페이지에서 기사 본문을 가져오는 것이 목표이다.
그렇다면, 기사 본문을 가져오는 코드를 작성하도록 하겠다. 크롤링은 BeautifulSoup, requests를 사용하며, TextRank 프로젝트인 만큼 크롤링 관련해서는 자세하게 설명은 따로 하지 않겠다(관련 질문은 댓글로🖐).
from bs4 import BeautifulSoup
import requests
import re
#웹페이지 스크립트 가져오기
date = input('날짜를 입력해주세요(ex.20210714):') #날짜에 따라 크롤링 가능
url = "https://finance.naver.com/news/news_list.nhn?"
params = {'mode' : 'RANK',
'date' : date}
resp = requests.get(url, params)
print(resp)
soup = BeautifulSoup(resp.content, 'lxml')
#각 뉴스기사의 링크 크롤링하기
url_list = soup.find('div','hotNewsList').find_all('a')
news_url_list = []
for url in url_list :
news_url_list.append('https://finance.naver.com' + url['href'])
print(len(news_url_list)) #25출력 => 한 페이지당 25개의 뉴스기사있음
news_url_list[0]
# 링크가 주어지면, 기사 제목과 본문을 크롤링하는 코드
def get_news_by_url(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'} # 각자 본인의 User-Agent 정보 입력
res = requests.get(url, headers = headers)
bs = BeautifulSoup(res.content, 'html.parser')
#제목
title = bs.find('div','article_info').find('h3').string
title = re.sub('\t|\r|\n| ', '', title)
#본문
content = bs.find('div','articleCont').text
content = re.sub('\xa0|\t|\r|\n|', '', content)
return title + content
#25개의 url을 통해 각 뉴스기사 페이지의 본문을 가져온다!
news_content = []
for url in news_url_list :
news_content.append(get_news_by_url(url))
이렇게 코드를 실행하고 나면, news_content라는 리스트에 한 날짜에 대해서 가장 많이 본 뉴스 25개의 기사 본문이 저장된다. 위에 날짜를 입력하는 코드가 있는데, 2021년 7월 13일에 가장 많이 본 뉴스기사를 보기 위해 '210713'을 입력해주었고, 한 기사 본문이 잘 크롤링되었는지 출력해보았다. 그 결과 아래와 같다.
news_content[10]
'미국도2분기어닝시즌시작...투자포인트는? [[오늘의 포인트]]월스트리트미국도 대형은행을 시작으로 어닝시즌 막이 오른다. 미국 대형주들의 2분기 실적은 올 2분기에 65% 이상 급증할 것으로 기대되고 있다. 다만 깜짝실적이 연례화되고, 글로벌 경제 환경이 불투명해지면서 실제 실적보다는 기업들의 가이던스(실적 전망) 발표에 더 관심이 쏠리고 있다. ━2분기 실적 기대감에 美 사상 최고치...S&P500 PER 22배 ━주요 외신에 따르면 13일(현지시간)에는 △JP모건체이스 △골드만삭스 △펩시코가 14일에는 △뱅크오브아메리카 △웰스파고 △블랙록 △씨티그룹이, 15일에는 △모간스탠리 △알코아 △유나이티드헬스가 실적을 발표할 예정이다. 실적 기대감에 ...(생략)
이렇게 기사 본문이 잘 크롤링되었다! 이제 TextRank를 구현하여 기사들을 요약해보도록 하겠다.
[2] TextRank 모델 만들기
1. 모듈설치 & Setting
먼저, cmd창에 필요한 라이브러리를 설치해준다.
pip install jpype1
pip install konlpy
pip install scikit-learn
그리고 아래 코드를 실행해준다.
from konlpy.tag import Kkma
from konlpy.tag import Twitter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import normalize
import numpy as np
2. 자연어처리
필요한 모듈을 설치해주었다면, 이제 자연어처리를 해주어야 하는데, 각 문장마다 단어의 순위를 매기기 위해서 텍스트를 명사형태의 단어 집합으로 만드는 자연어처리를 해주어야 한다. 그전에 우선 1)꼬꼬마분석기를 사용하여 text를 문장 단위로 나눈 뒤 리스트 자료형으로 저장을 해주었다. 추가로 문자열의 길이가 10이하인 문장은 이전 문장과 합쳐지도록 해주었다.
#꼬꼬마분석기
kkma = Kkma()
#text를 입력받아 Kkma.sentences()를 이용해 문장단위로 나눈 뒤 sentences로 리턴
def text2sentences(text):
sentences = kkma.sentences(text) #text일 때 문장별로 리스트 만듦
for idx in range(0, len(sentences)): #길이에 따라 문장 합침(위와 동일)
if len(sentences[idx]) <= 10:
sentences[idx-1] += (' ' + sentences[idx])
sentences[idx] = ''
return sentences
그렇다면 위에서 크롤링한 한 뉴스기사를 가져와 적용해보도록 하겠다. for문을 이용해 25개의 모든 기사에 대해 텍스트 요약을 해도 되지만 우선적으로 1개의 본문이 어떻게 요약되는지 보려고 하나의 기사만 적용시켜보았다.
#기사본문 가져오기(리스트형태로)
sentences = text2sentences(news_content[10])
위와 같이 코드를 실행한 뒤, sentences 변수를 출력해보면 하나의 문자열로 저장되어 있었던 텍스트가 리스트 형태로 각 문장이 저장되어 있는 것을 확인할 수 있을 것이다.
그러면 이제 각 문장을 2)명사 형태로 변경해주어야 하는데, 이에 대해서 Twitter.nouns()를 사용해주었다. 아래 코드를 실행해보자.
twitter = Twitter()
#불용어제거
stopwords = ['머니투데이' , "연합뉴스", "데일리", "동아일보", "중앙일보", "조선일보", "기자","아", "휴", "아이구", "아이쿠", "아이고", "어", "나", "우리", "저희", "따라", "의해", "을", "를", "에", "의", "가",]
def get_nouns(sentences):
nouns = []
for sentence in sentences:
if sentence is not '':
nouns.append(' '.join([noun for noun in twitter.nouns(str(sentence))
if noun not in stopwords and len(noun) > 1]))
return nouns
추가로 불용어 제거까지 해주는 함수를 만들었는데, 아래와 같이 리스트 형태의 본문 sentences를 적용해준다.
nouns = get_nouns(sentences)
어떻게 적용이 되었는지 첫 번째 문장과 변경하기 전 첫 번째 문장을 출력해 비교해보았다.
nouns = get_nouns(sentences)
print(sentences[0])
print()
print(nouns[0])미국도 2 분기 어 닝 시즌 시작... 투자 포인트는? [[ 오늘의 포인트]] 월 스트리트 미국도 대형은행을 시작으로 어 닝 시즌 막이 오른다.
미국 분기 시즌 시작 투자 포인트 오늘 포인트 스트리트 미국 대형 은행 시작 시즌
첫 번째 문장은 Twitter.nouns()를 적용하기 전 문장, 그 아래 문장은 Twitter.nouns()를 적용한 후의 문장으로, 명사형태로 바뀌었음을 확인할 수 있다. 여기까지 했다면 이제 요약할 텍스트에 대한 준비는 끝이다.
3. TF-IDF 모델 생성 및 그래프 생성
필요한 자연어처리를 해주었다면, 이제 TF-IDF 모델을 만들어주어야 한다.
TF-IDF(Term Frequency-Inverse Document Frequency)란 단어의 빈도와 역 문서 빈도를 사용하여 DTM 내의 각 단어들마다의 중요한 정도를 가중치로 주는 방법을 말한다. 또한 TF-IDF는 TF와 IDF를 곱한 값을 의미하기도 하는데, TF는 특정 문서에서 특정 단어의 등장 횟수를, IDF는 특정 단어가 등장한 문서의 수에 반비례하는 수를 뜻한다. (TF-IDF가 더 궁금하다면!)
한편, 앞에서 TextRank 값을 구하는 수식에 대해 설명할 때, 단어 i와 j 사이의 가중치를 뜻하는 'Wji'가 있었다. 지금 만들어야 할 값이 바로 Wij이다. 따라서 이러한 값을 TF-IDF 모델을 통해 구해보도록 하겠다.
먼저, 앞에서 명사로 이루어진 문장리스트를 입력받아 sklearn의 TfidVectorizer.fit_transform을 이용하면 TF-IDF matrix를 만들 수 있다고 한다. 그리고나서 TF-IDF matrix를 이용해 Sentence Graph를 리턴시키는 함수를 만들어주면 된다(코드 도움). 아래 코드를 실행해 보자.
tfidf = TfidfVectorizer()
cnt_vec = CountVectorizer()
graph_sentence = []
def build_sent_graph(sentence):
tfidf_mat = tfidf.fit_transform(sentence).toarray()
graph_sentence = np.dot(tfidf_mat, tfidf_mat.T)
return graph_sentence
sent_graph = build_sent_graph(nouns)
위 코드를 실행하면 sent_graph라는 변수에 요약할 문장 단위에 대한 sentence graph가 생성된다. sent_graph를 출력해줌으로써 그 형태를 확인할 수 있다.
[[1. 0.20095813 0. ... 0. 0. 0. ]
[0.20095813 1. 0.09674027 ... 0. 0. 0. ]
[0. 0.09674027 1. ... 0.03337874 0. 0. ]
...
[0. 0. 0.03337874 ... 1. 0. 0. ]
[0. 0. 0. ... 0. 1. 0. ]
[0. 0. 0. ... 0. 0. 1. ]]
반면, 이번엔 단어 단위에 대한 word graph를 만들고, {idx : word} 형태의 딕셔너리를 만들기 위해 sklearn의 CountVectorizer.fit_transform을 사용해준다. 단어에 대해서도 word graph를 만드는 이유는 가장 순위가 높은 문장들 말고도 가장 순위가 높은 keyword를 찾아보려고 하기 위함이다.
def build_words_graph(sentence):
cnt_vec_mat = normalize(cnt_vec.fit_transform(sentence).toarray().astype(float), axis=0)
vocab = cnt_vec.vocabulary_
return np.dot(cnt_vec_mat.T, cnt_vec_mat), {vocab[word] : word for word in vocab}
words_graph, idx2word = build_words_graph(nouns)
위 코드를 실행해주고, 마찬가지로 words_graph와 idx2word를 출력하면 아래와 같은 결과가 나온다.
<words_graph 출력결과>
[[1. 0. 0. ... 0. 0. 0.]
[0. 1. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 1.]
...
[0. 0. 0. ... 1. 0. 0.]
[0. 0. 0. ... 0. 1. 0.]
[0. 0. 1. ... 0. 0. 1.]]
<idx2word 출력결과>
{80: '미국', 94: '분기', 136: '시즌', 134: '시작', 228: '투자', 234: '포인트', 157: '오늘', 131: '스트리트', 50: '대형', 172: '은행', 51: '대형주', 137: '실적', 175: '이상', 19: '급증', 40: '다만', 25: '깜짝', 153: '연례', ... }
4. TextRank 구현하기
이제 드디어 위해서 구한 가중치 그래프를 이용하여 TextRank 알고리즘(수식)에 넣어 점수를 매기고, 순위가 높은 순으로 정렬한 뒤, 요약할 문장의 개수만큼 출력을 해주어야 한다. 아래 get_ranks 함수가 바로 TextRank 값을 계산하는 코드에 해당된다.
def get_ranks(graph, d=0.85): # d = damping factor
A = graph
matrix_size = A.shape[0]
for id in range(matrix_size):
A[id, id] = 0 # diagonal 부분을 0으로
link_sum = np.sum(A[:,id]) # A[:, id] = A[:][id]
if link_sum != 0:
A[:, id] /= link_sum
A[:, id] *= -d
A[id, id] = 1
B = (1-d) * np.ones((matrix_size, 1))
ranks = np.linalg.solve(A, B) # 연립방정식 Ax = b
return {idx: r[0] for idx, r in enumerate(ranks)}
그러면 이제 위에서 구한 sent_graph를 TextRank 수식이 담긴 함수 get_ranks에 넣어 점수를 매겨준다.
sent_rank_idx = get_ranks(sent_graph) #sent_graph : sentence 가중치 그래프
sent_rank_idx
{0: 0.9559671008853996,
1: 1.3002149462559782,
2: 1.639021060550871,
3: 0.9843074628398639,
4: 1.242104677385347,
5: 1.3238319389820223,
6: 0.15000000000000002,
7: 1.2474715883614027,
8: 0.6653860796212921,
9: 0.4071473637413339,
10: 1.2505464216346451
...
32: 0.2462151152831532}
그리고 sorted() 함수를 이용하여 점수가 큰 값부터 인덱스를 나열시키도록 했다.
sorted_sent_rank_idx = sorted(sent_rank_idx, key=lambda k: sent_rank_idx[k], reverse=True)
sorted_sent_rank_idx를 출력해보면 [2, 25, 27, 28, 23, 11, 24, 16, 14, 5, 1, 10, 7, 4, 21, 3, 0, 19, 26, 18, 12, 30, 20, 22, 8, 29, 15, 13, 9, 17, 32, 31, 6] 이 출력되는데, 앞에 있는 인덱스의 문장일수록 점수가 가장 높게 매겨졌음을 나타낸다.
마찬가지로 words_graph도 TextRank 수식에 따라 점수를 매기고 정렬시켜준다.
word_rank_idx = get_ranks(words_graph)
sorted_word_rank_idx = sorted(word_rank_idx, key=lambda k: word_rank_idx[k], reverse=True)
5. 요약하기 실행
기사 본문에 대해서 각 문장과 단어마다의 점수를 매기고, 인덱스 값을 정렬해놨으니 이제 TextRank값이 높은 문장들을 출력하기만 하면 된다. 따라서 아래와 같이 요약할 문장의 수를 입력하면 그 문장의 개수만큼 요약해주는 함수를 만들어준다.
def summarize(sent_num=5):
summary = []
index=[]
for idx in sorted_sent_rank_idx[:sent_num]:
index.append(idx)
index.sort()
# print(index)
for idx in index:
summary.append(sentences[idx])
for text in summary :
print(text)
print("\n")
위와 같이 summarize() 함수를 만들어 주었는데, 기본적으로 요약할 문장을 5개로 지정해주었다. 이제 드디어 이 함수를 실행해주면, 아래와 같이 5개의 문장으로 뉴스 기사 본문이 요약된다!
summarize()다만 깜짝 실적이 연례화 되고, 글로벌 경제 환경이 불투명 해지면서 실제 실적보다는 기업들의 가이 던스( 실적 전망) 발표에 더 관심이 쏠리고 있다.
BMO 캐피털 마켓의 브라 이언 벨 스키 수석 투자 전략가는 " 지난해 코로나 19로 셧다운에 들어가면서 기업들은 가이 던스( 실적 전망치 )를 하향조정했다 "며 " 기업들은 소극적으로 가이 던 스를 제시하고, 깜짝 실적을 내놓는 문화가 지속되고 있다" 고 꼬집었다.
벨 스키 수석 투자 전략가는 " 이번 실적 발표일에는 S&P 500 지수 기업 대다수가 가이 던 스를 새로 제시할 것" 이라고 예상했다.
우리나라 기업들이 피크 아웃( 고점 통과) 우려에 시달리고 있는 것과 대조적으로 미국 기업들의 이익 성장 기대감은 여전히 살아 있는 상황이다.
앨리 인 베스트의 칼리 보 스트 선임 투자 전략가는 " 이익 성장은 둔화될 수 있지만 다음 2 분기 동안에도 S&P 500 기업들의 이익은 두 자릿수 성장이 가능하다 "며 " 강한 경제 성장이 나중에 온다는 이유만으로 시장에 대한 믿음을 잃어서는 안 된다" 고 밝혔다.
이렇게 5개의 문장이 출력되었는데, 3개의 문장으로 요약하고 싶다면 summarize(3)이라고 입력해주면 된다. 한편, 출력 결과를 보면 기사 본문에서 중요한 문장이 잘 선택된 것 같다.
이번에는 word_graph를 이용하여 어떤 키워드가 중요했는지를 찾는 함수를 만들고자 한다. 마찬가지로 출력할 단어는 10개로 기본값을 지정해주었다.
def keywords(word_num=10):
keywords = []
index=[]
for idx in sorted_word_rank_idx[:word_num]:
index.append(idx)
#index.sort()
for idx in index:
keywords.append(idx2word[idx])
print(keywords)
위와 같이 입력하고 실행했다면 keywords를 출력해보겠다.
keywords()['실적', '기업', '이익', '시장', '전략', '분기', '지수', '투자', '사상', '최고']
keywords() 실행 결과, 위와 같이 가장 점수가 높은 10개의 단어가 출력되었다. 요약된 문장과 추출된 단어를 비교해보면 주요 keywords들이 요약된 문장에 많이 포함되었음을 살펴볼 수 있다. 즉, 높은 순위의 단어가 많이 포함되어 있을수록 그 문장의 점수도 높아지게 되는 것 같다.
그 밖에도 다른 뉴스 기사들을 요약해보았는데 요약된 내용과 주요 keywords는 다음과 같다.
<뉴스기사본문 링크>
https://finance.naver.com/news/news_read.nhn?article_id=0001861057&office_id=016&mode=RANK&typ=0
<요약>
[ 해외주식 길라잡이]‘ 제 4차 산업혁명시대’ 인간과기계의 공존에 투자하는 로봇 ETF 주목경기회복과 더불어 로봇산업과 관련된 지표들도 빠르게 상승하는 중이다.
주로 제조업에서 사용되는 산업용 로봇시장의 성장과 함께 주목을 끄는 투자 포인트는 인공지능과 기계를 결합시켜 각종 서비스를 제공하는 서비스용 로봇시장의 성장이다.
세계 산업용 로봇의 경기를 반영하는 일본의 로봇 수출 동향도 올해 이후 빠른 상승세를 유지하고 있다.
산업용 로봇 수요의 강력한 회복속도도 중요하지만, 훨씬 더 관심을 끄는 부분은 급속히 확대되고 있는 서비스용 로봇의 활용분야다.
이 ETF는 세계 주요 로봇 관련 제품 서비스를 제공하는 기업들에 투자하며, 투자 범위는 로봇과 관련된 밸류 체인 전반이다.
<keywords>
['로봇', '관련', '산업혁명', '산업', '활용', '성장', '기계', '투자', '제조업', '일본']
<뉴스기사본문 링크>
https://finance.naver.com/news/news_read.nhn?article_id=0005478481&office_id=421&mode=RANK&typ=0
<요약>
주식재산 100억 넘는 월급쟁이 임원 18명 …1 천억 주식 갑부는 4명 CXO 연구소, 시가 총액 100대 기업 임원 주식 평가액 조사© 뉴스 1( 서울= 뉴스 1) 류 정민 기자 = 국내 시가 총액 100대 기업에서 주식재산을 100억원 넘게 소유한 비( 非) 오너 임원이 18명인 것으로 조사됐다.
셀 트리 온 기우성 대표이사는 326억원으로 6위를 차지했다.
같은 기간 셀 트리 온 주식이 29만 8500원에서 26만 2000원으로 떨어지면서 기 대표이사의 주식가치도 감소했다.
보유주식이 기존 20 만주에서 1 만주 늘고, 삼성전자 1 주당 주식가치도 5만 9200원에서 7만 9400원으로 상승한 요인이 작용했기 때문이다.
100명이 넘는 주식재산 10억원이 넘는 비 오너 임원이 가장 많이 포진된 곳은 셀 트리 온인 것으로 조사됐다.
<keywords>
['주식', '임원', '대표이사', '조사', '평가', '재산', '삼성', '게임', '기업', '보유']
<뉴스기사본문 링크>
https://finance.naver.com/news/news_read.nhn?article_id=0010606463&office_id=003&mode=RANK&typ=0
<요약>
상장사 ,IPO도 활발… 청약 경쟁률 2년 만에 2.7 배[ 서울= 뉴 시스] 2011-2021 년 공모금액 및 청약 경쟁률 현황과 비중 변화.( 그래픽 =CEO 스코어 제공) 2021.7.14 photo@newsis .com[ 서울= 뉴 시스] 박 정규 기자 = 국내 상장사의 기업공개 (IPO) 청약 경쟁률이 최근 10년 간 3 배 증가한 것으로 나타났다.
기업 별로는 올해 1월 상장한 엔비티의 청약 경쟁률이 4398대 1로 가장 높았다.
일 기업평가사이트 CEO 스코어에 따르면 2011년부터 올해 상반기까지 IPO를 진행한 647개 상장사의 청약 경쟁률과 공모금액, 청약 증거금 등 IPO 현황을 조사한 결과 상장사 평균 청약 경쟁률은 2011년 438.7대 1에서 올해 6월 1376.9대 1로 10년 간 약 3 배 증가했다.
기업 별로 청약 경쟁률이 가장 높았던 기업은 올해 1월 21일 상장한 엔비티다.
2014년 12월 18일 상장한 제일 모직은 당시 공모가격 5만 3000원에 485조 2210억원의 청약 증거금이 모였다.
<keywords>
['금액', '청약', '경쟁률', '상장', '스코어', '하반기', '증거', '공모', '증가', '코로나']
[3] Result
이렇게 TextRank를 실제로 구현해보고, 크롤링한 뉴스 기사 데이터를 이용하여 텍스트 요약과 주요 키워드를 출력해보았다. 또한, PageRank의 알고리즘을 텍스트에도 이용하여 요약을 하는 방법이 처음에는 이게 과연 중요한 문장들을 잘 추려낼까 싶었지만, 코드로 구현하면서 들여다보니 단어의 빈도와 다른 단어 또는 문장과의 관계 등을 분석하여 요약이 나름대로 일리있게 이루어졌다는 것을 알 수 있었다. 사람도 요약을 할 때 자주 나오는 단어를 보고, 문장 간의 원인/결과와 같은 관계를 파악하듯 TextRank도 이를 굉장히 잘 나타낸 것 같다.
하지만 한편으로는 추출적요약이다보니 그 나름대로의 한계는 있는 것 같다. 왜냐하면 중요한 상위 몇 개의 문장들만 뽑아낸거지, 이 문장들이 전체 내용을 요약해주는 것은 아니기 때문이다. 따라서 다음 프로젝트에서는 추상적요약에 대해 다뤄보도록 하겠다.
|| Reference
'PROJECT' 카테고리의 다른 글
| [에어] InceptionV3으로 한국어(한글) 이미지 캡셔닝(Image Captioning) 모델 만들기 (파이썬/Colab) (4) | 2021.08.26 |
|---|---|
| [에어] Memory Networks (MemNN) 로 뉴스 기사 QnA(질의응답) 예측 모델 만들기 (파이썬/Colab) (0) | 2021.08.04 |
| [에어] Transformer 모델로 오피스 챗봇 만들기 (파이썬/Colab) (0) | 2021.06.07 |
| [에어] 7가지 감정의 한국어 대화, 'KOBERT'로 다중 분류 모델 만들기 (파이썬/Colab) (3) | 2021.05.27 |
| [에어] 일상적인 한국어 대화 유형(일상/연애) 'BERT'로 분류 모델 만들기 (파이썬/colab) (0) | 2021.05.18 |



