에어 프로젝트
#3 Transformer 모델로 오피스 챗봇 만들기

요즘 여러 회사에서 인공지능 비서의 도입이 증가하고 있는데, 인공지능 비서는 주로 챗봇의 형태로 기본적인 대화부터 하루 일과, 해야 할 업무, 스케줄 등을 알려주곤 한다. 또는 특정 업무에 특화되어 단순 반복적인 업무를 대신하는 인공지능 비서가 있는데, 이러한 인공지능 비서는 사용자의 업무 효율을 높이곤 한다.
이번 에어 프로젝트에서는 트랜스포머(Transformer) 모델을 이용하여 간단한 대화가 가능한 인공지능 비서 챗봇을 만들어 보고자 한다. 그동안 지난 에어 프로젝트들에서 질문 텍스트가 어떠한 유형인지 구분하는 챗봇 모델을 만들었다면, 이번 에어 프로젝트에서는 회사생활과 관련된 질의에 대해 적절한 답변을 하는 챗봇 모델을 만들어 보고자 한다.
|| 트랜스포머(Transformer)란?
챗봇 모델을 만들어 보기 전에, 트랜스포머(Transformer)에 대해 먼저 간단하게 알아보고자 한다.
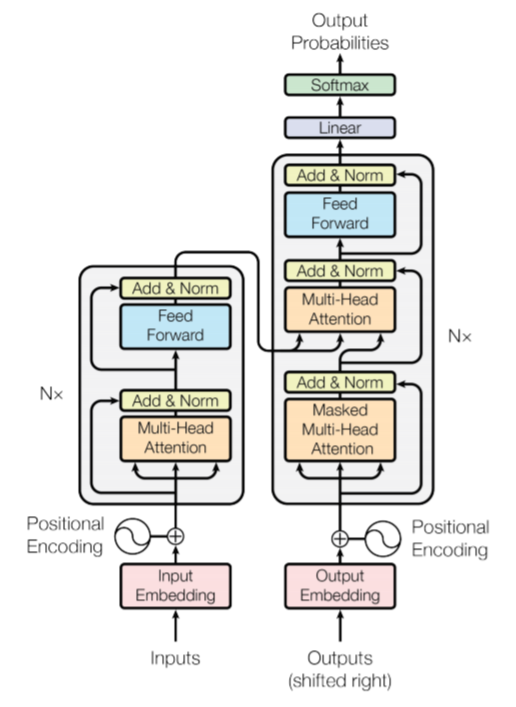
트랜스포머는 2017년 발표된 "Attention is All You Need" 라는 논문에서 나온 모델인데, 논문 제목과 같이 어텐션(Attention) 이라는 구조로 구현된 모델이다. 위와 같은 구조를 가지는 트랜스포머는 RNN 구조를 사용하지 않고, 어텐션 구조를 갖는 인코더(왼쪽 부분)와 디코더(오른쪽 부분)가 쌓아져 있는 형태를 갖고 있는데, 그 성능이 RNN보다 훨씬 더 우수하다고 한다.
한편, 인코더와 디코더로 단어의 순서 정보가 고려된 값(임베딩 벡터)이 들어가게 되는데, 단어의 위치 정보를 얻기 위해선 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하고, 이를 포지셔널 인코딩이라고 한다. 더 자세한 트랜스포머의 특징 및 인코딩, 디코딩에 대해선 코드를 구현하며 살펴보도록 하겠다.
|| 트랜스포머를 이용하여 챗봇 만들기
이번 프로젝트에서는 일상 대화 및 오피스 대화 데이터를 트랜스포머 모델로 학습시켜, 질의에 대해 적절한 답변을 하는 챗봇을 만들어보고자 한다. 코드는 "트랜스포머(Transformer)" 코드를 바탕으로 일부분만 변형하여 작성하였고, 학습 데이터는 참고한 코드에서 사용된 Chatbot_data(일상대화)와 추가로 학습할 오피스데이터를 사용하였다.
코드는 파이썬으로 Colab에서 작성하였고, GPU를 사용하였다. 이제 트랜스포머의 특징 및 핵심적인 코드를 살펴보며 오피스 대화 챗봇을 만들어 보도록 하겠다.
그 외 환경
- batch size = 64
- buffer size = 20000
- Colab / GPU
- epochs = 50
1) 데이터 준비
먼저, 환경변수 셋팅을 해주고, 학습시킬 데이터를 준비한다. 총 두 가지 데이터를 준비하는데, 일상대화 데이터는 깃허브에서 불러오고, 텍스트 파일로 이루어진 오피스 대화 데이터는 구글드라이브에 업로드 한 뒤 계정을 연동한 뒤 불러와주었다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import urllib.request
import time
import tensorflow_datasets as tfds
import tensorflow as tf
urllib.request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData%20.csv", filename="ChatBotData.csv")
data = pd.read_csv('ChatBotData.csv')
data = data[0:5290]
해당 데이터셋에서 일상 관련 데이터가 5290행까지라서 data[0:5290]으로 불러와줬다. 일상 대화 데이터는 아래와 같은 형식을 갖고 있다.
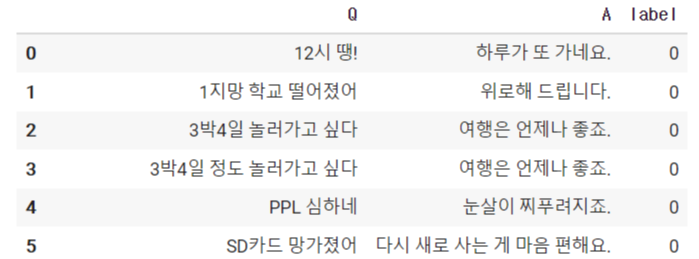
다음으로 텍스트 파일 형식의 오피스 대화 데이터를 불러와 같은 형식으로 전처리를 해준다.
#구글드라이브 연동
from google.colab import drive
drive.mount('/content/drive')
f = open(r'/content/drive/MyDrive/파이썬공부/챗봇/대화데이터_일상_오피스.txt',"r")
lines = f.readlines()
Q = []
A = []
for i in range(len(lines)) :
if i%2 == 0 :
Q.append(lines[i][2:-1])
A.append(lines[i+1][2:-1])
import pandas as pd
df = pd.DataFrame()
df['Q'] = Q
df['A'] = A
df['label'] = 1
이렇게 전처리를 해주면 오피스 대화 데이터는 아래의 형태를 가지게 된다.

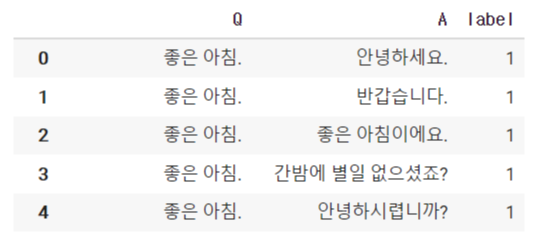
이 데이터의 경우 동일한 질문에 대한 다른 답변으로 이루어진 데이터가 꽤 있는 것 같다.
이제 위 두 데이터를 concat() 함수를 합쳐서 하나의 데이터프레임으로 나타내주도록 한다.
train_data = pd.concat([data, df],ignore_index=True)
len(train_data)를 통해 전체 데이터의 갯수를 구하면 총 6615개가 나오며, 마지막으로 데이터를 랜덤으로 섞은 뒤 데이터 준비를 끝낸다.
train_data = train_data.sample(frac=1).reset_index(drop=True)
(2) 단어 집합 생성
한편, 문장 그대로를 학습 모델에 넣으면, 모델이 인식을 할 수 없기 때문에 단어 집합을 만들어 준 뒤, 정수 인코딩과 패딩을 해주는 작업을 거쳐야 한다. (이부분은 참조한 코드에서 따로 변형을 하지 않았다)
# 특수기호 띄어쓰기
questions = []
for sentence in train_data['Q']:
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
questions.append(sentence)
answers = []
for sentence in train_data['A']:
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
answers.append(sentence)
#서브워드텍스트인코더 사용
tokenizer = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
questions + answers, target_vocab_size=2**13)
START_TOKEN, END_TOKEN = [tokenizer.vocab_size], [tokenizer.vocab_size + 1]
VOCAB_SIZE = tokenizer.vocab_size + 2
print('임의의 질문 샘플을 정수 인코딩 : {}'.format(tokenizer.encode(questions[20])))
MAX_LENGTH = 40
# 정수 인코딩 & 패딩
def tokenize_and_filter(inputs, outputs):
tokenized_inputs, tokenized_outputs = [], []
for (sentence1, sentence2) in zip(inputs, outputs):
# encode(토큰화 + 정수 인코딩), 시작 토큰과 종료 토큰 추가
sentence1 = START_TOKEN + tokenizer.encode(sentence1) + END_TOKEN
sentence2 = START_TOKEN + tokenizer.encode(sentence2) + END_TOKEN
tokenized_inputs.append(sentence1)
tokenized_outputs.append(sentence2)
# 패딩
tokenized_inputs = tf.keras.preprocessing.sequence.pad_sequences(
tokenized_inputs, maxlen=MAX_LENGTH, padding='post')
tokenized_outputs = tf.keras.preprocessing.sequence.pad_sequences(
tokenized_outputs, maxlen=MAX_LENGTH, padding='post')
return tokenized_inputs, tokenized_outputs
questions, answers = tokenize_and_filter(questions, answers)
여기까지 코드를 실행해준 뒤, 샘플로 questions[0]을 출력해보면 다음가 같이 정수 인코딩과 패딩이 된 결과가 출력된다.
[10023 1324 18 5 569 1 10024 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
마지막으로, 인코더와 디코더의 입력 데이터가 되도록 배치 크기로 데이터를 묶어주면 된다.
BATCH_SIZE = 64
BUFFER_SIZE = 20000
dataset = tf.data.Dataset.from_tensor_slices((
{
'inputs': questions,
'dec_inputs': answers[:, :-1] # 디코더의 입력. 마지막 패딩 토큰 제거
},
{
'outputs': answers[:, 1:]
},
))
dataset = dataset.cache()
dataset = dataset.shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
(3) 트랜스포머 모델 만들기
아래 코드는 트랜스포머를 구현하는 코드이다. 코드의 각 자세한 설명은 해당 코드를 참조한 이 글을 참조하길 바란다.
def transformer(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="transformer"):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1, None, None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='dec_padding_mask')(inputs)
# 인코더의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
def get_angles(self, position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position=tf.range(position, dtype=tf.float32)[:, tf.newaxis],
i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :],
d_model=d_model)
# 배열의 짝수 인덱스(2i)에는 사인 함수 적용
sines = tf.math.sin(angle_rads[:, 0::2])
# 배열의 홀수 인덱스(2i+1)에는 코사인 함수 적용
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...]
print(pos_encoding.shape)
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]
def create_padding_mask(x):
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
# (batch_size, 1, 1, key의 문장 길이)
return mask[:, tf.newaxis, tf.newaxis, :]
# 디코더의 첫번째 서브층(sublayer)에서 미래 토큰을 Mask하는 함수
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
padding_mask = create_padding_mask(x) # 패딩 마스크도 포함
return tf.maximum(look_ahead_mask, padding_mask)
#encoder
def encoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 멀티-헤드 어텐션 (첫번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': padding_mask # 패딩 마스크 사용
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# d_model을 num_heads로 나눈 값.
# 논문 기준 : 64
self.depth = d_model // self.num_heads
# WQ, WK, WV에 해당하는 밀집층 정의
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
# WO에 해당하는 밀집층 정의
self.dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v를 split하는 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs[
'value'], inputs['mask']
batch_size = tf.shape(query)[0]
# 1. WQ, WK, WV에 해당하는 밀집층 지나기
# q : (batch_size, query의 문장 길이, d_model)
# k : (batch_size, key의 문장 길이, d_model)
# v : (batch_size, value의 문장 길이, d_model)
# 참고) 인코더(k, v)-디코더(q) 어텐션에서는 query 길이와 key, value의 길이는 다를 수 있다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 2. 헤드 나누기
# q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
# (batch_size, query의 문장 길이, num_heads, d_model/num_heads)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model))
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs = self.dense(concat_attention)
return outputs
def scaled_dot_product_attention(query, key, value, mask):
# query 크기 : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기 : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기 : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬.
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 스케일링
# dk의 루트값으로 나눠준다.
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 마스킹. 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행된다.
# attention weight : (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weights = tf.nn.softmax(logits, axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output = tf.matmul(attention_weights, value)
return output, attention_weights
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두번째 서브층)
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
tf.keras.backend.clear_session()
# Hyper-parameters
D_MODEL = 256
NUM_LAYERS = 2
NUM_HEADS = 8
DFF = 512
DROPOUT = 0.1
model = transformer(
vocab_size=VOCAB_SIZE,
num_layers=NUM_LAYERS,
dff=DFF,
d_model=D_MODEL,
num_heads=NUM_HEADS,
dropout=DROPOUT)
# (1, 10025, 256) 출력
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
def loss_function(y_true, y_pred):
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')(y_true, y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
loss = tf.multiply(loss, mask)
return tf.reduce_mean(loss)
learning_rate = CustomSchedule(D_MODEL)
optimizer = tf.keras.optimizers.Adam(
learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
def accuracy(y_true, y_pred):
# 레이블의 크기는 (batch_size, MAX_LENGTH - 1)
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
return tf.keras.metrics.sparse_categorical_accuracy(y_true, y_pred)
model.compile(optimizer=optimizer, loss=loss_function, metrics=[accuracy])
여기까지 코드 실행을 해주었다면 앞서 준비한 dataset으로 지정한 epochs 만큼 모델을 학습시킨다.
EPOCHS = 50
model.fit(dataset, epochs=EPOCHS)
50번 학습을 시키는 데 10분도 채 걸리지 않았다. 50번째 학습 결과, loss 값은 0.0145로 측정되었다.
(4) 챗봇 평가하기
학습을 시켰다면, 학습시킨 챗봇에 새로운 문장을 넣어 평가하고자 한다. 새로운 문장 역시 인코더 입력 형식으로 변형시켜야 하기 때문에 아래의 코드를 실행해준다.
def evaluate(sentence):
sentence = preprocess_sentence(sentence)
sentence = tf.expand_dims(
START_TOKEN + tokenizer.encode(sentence) + END_TOKEN, axis=0)
output = tf.expand_dims(START_TOKEN, 0)
# 디코더의 예측 시작
for i in range(MAX_LENGTH):
predictions = model(inputs=[sentence, output], training=False)
# 현재(마지막) 시점의 예측 단어를 받아온다.
predictions = predictions[:, -1:, :]
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
# 만약 마지막 시점의 예측 단어가 종료 토큰이라면 예측을 중단
if tf.equal(predicted_id, END_TOKEN[0]):
break
# 마지막 시점의 예측 단어를 출력에 연결한다.
# 이는 for문을 통해서 디코더의 입력으로 사용될 예정이다.
output = tf.concat([output, predicted_id], axis=-1)
return tf.squeeze(output, axis=0)
def predict(sentence):
prediction = evaluate(sentence)
predicted_sentence = tokenizer.decode(
[i for i in prediction if i < tokenizer.vocab_size])
print('Input: {}'.format(sentence))
print('Output: {}'.format(predicted_sentence))
return predicted_sentence
def preprocess_sentence(sentence):
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
return sentence
이제 predict() 함수에 문장을 입력하면 그거에 대한 결과가 출력된다. 아래 이미지는 새로운 문장을 넣었을 때 출력된 결과들이다.

"굿모닝"과 같은 데이터는 학습데이터에 있던 데이터지만, 학습 데이터에 "야근"이 포함되는 문장이 없는데도 적절한 답변이 출력되었다. 이를 통해 학습한 챗봇 모델이 입력한 문장에 대해서 상당히 적절한 답변을 하는 것을 확인할 수 있다.
|| 트랜스포머 학습 결과 및 보완점
Attention 알고리즘을 이용한 트랜스포머 모델을 직접 만든 뒤, 약 6600개 밖에 안되는 데이터로 학습시켰지만 성능이 상당히 좋았다. 특히 오피스 대화 데이터는 전체 데이터의 5분의 1밖에 되지 않지만 일상 대화 데이터와 같이 학습을 시킨 결과, 학습데이터에 없던 문장을 입력해도 적절한 답변을 출력하는 것을 확인할 수 있었다. 따라서 특정 대화에 특화된 데이터셋이 많다면 아주 성능이 좋은 챗봇이 만들어지지 않을까 생각된다.
또한 형식적인 일반 대화 말고도, 현재 날씨, 해야할 일, 남은 퇴근시간 등과 관련된 질문(일반화 할 수 없는 질문)을 받았을 때, 그 상황에 맞는 답변이 출력되도록 구현하면 더 쓸모가 있는 챗봇이 되지 않을까 싶다.
|| Reference
'PROJECT' 카테고리의 다른 글
| [에어] InceptionV3으로 한국어(한글) 이미지 캡셔닝(Image Captioning) 모델 만들기 (파이썬/Colab) (4) | 2021.08.26 |
|---|---|
| [에어] Memory Networks (MemNN) 로 뉴스 기사 QnA(질의응답) 예측 모델 만들기 (파이썬/Colab) (0) | 2021.08.04 |
| [에어] TextRank 로 크롤링한 뉴스 기사 요약 모델 만들기 (파이썬/Colab) (1) | 2021.07.15 |
| [에어] 7가지 감정의 한국어 대화, 'KOBERT'로 다중 분류 모델 만들기 (파이썬/Colab) (3) | 2021.05.27 |
| [에어] 일상적인 한국어 대화 유형(일상/연애) 'BERT'로 분류 모델 만들기 (파이썬/colab) (0) | 2021.05.18 |



