엑셀 파일에 있는 데이터를 분석하기 위해 파일을 불러와 데이터 프레임으로 나타낼 때, 모든 데이터가 함께 출력됩니다. 이때 필요 없는 행이 있다면 전처리 과정에서 삭제를 해주어야 하는데요, 데이터 프레임으로 불러올 때 마지막 행 또는 아랫부분의 행을 빼고 가져오는 방법이 있습니다.
바로, read_excel() 함수에서 skipfooter 라는 모듈을 이용하는 것인데요, 말 그대로 하단 부분을 스킵하고 나머지 부분만을 불러오는 모듈입니다.
예를 들어, 아래와 같이 'sample.xlsx' 이라는 이름의 엑셀 파일이 있다고 가정해보겠습니다.
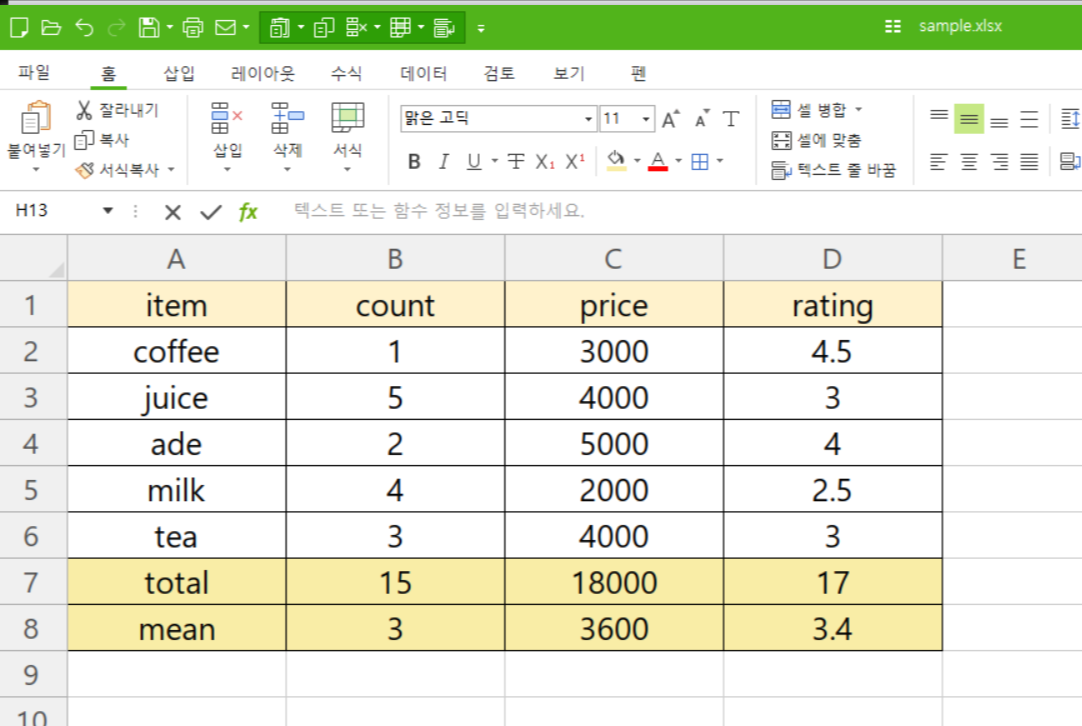
엑셀 파일에 있는 데이터를 살펴보자면 'item', 'count', 'price', 'rating' 이라는 칼럼이 있고, 해당 데이터가 2행부터 6행까지 나열되어 있으며, 7행에는 total이, 8행에는 mean에 대한 데이터가 담겨 있습니다.
이제 이 데이터를 데이터프레임으로 불러오겠습니다.
import pandas as pd
file = r"C:\Users\Dinolabs\Desktop\데이터분석\sample.xlsx" #해당 경로
df = pd.read_excel(file, sheet_name="Sheet1")
display(df)
item count price rating
0 coffee 1 3000 4.5
1 juice 5 4000 3.0
2 ade 2 5000 4.0
3 milk 4 2000 2.5
4 tea 3 4000 3.0
5 total 15 18000 17.0
6 mean 3 3600 3.4
출력된 값을 보면, 모든 데이터가 데이터프레임으로 잘 가져와졌음을 볼 수 있습니다.
하지만 여기서 만약 맨 아래에 있는 행을 제외하고 불러오고 싶다면, skipfooter 모듈을 사용하면 되는데요, 다음과 같이 코드를 입력하면 됩니다.
df1 = pd.read_excel(file, sheet_name="Sheet1", skipfooter = 1)
display(df1)
item count price rating
0 coffee 1 3000 4.5
1 juice 5 4000 3.0
2 ade 2 5000 4.0
3 milk 4 2000 2.5
4 tea 3 4000 3.0
5 total 15 18000 17.0
위 코드를 보면, skipfooter를 skipfooter = 1로 설정해주었는데요, 이는 맨 아래에서 첫 번째 행을 제외하고 불러오라는 뜻입니다.
그렇다면, 만약 skipfooter를 skipfooter = 2로 설정하면 어떻게 될까요?
바로 아래 결과처럼 맨 아래에서 두번째 까지의 행을 제외하고 나머지 데이터를 불러오게 된답니다.
df2 = pd.read_excel(file, sheet_name="Sheet1", skipfooter = 2)
display(df2)
item count price rating
0 coffee 1 3000 4.5
1 juice 5 4000 3.0
2 ade 2 5000 4.0
3 milk 4 2000 2.5
4 tea 3 4000 3.0
이렇게 skipfooter를 이용하여 엑셀 파일의 아래 부분 행을 제외한 나머지 데이터를 데이터프레임으로 불러오는 방법에 대해서 알아보았는데요, 다음 포스팅에서는 행을 선택적으로 불러오는 방법에 대해서 설명하도록 하겠습니다.
'BLOG > 데이터분석' 카테고리의 다른 글
| [데이터분석] 엑셀 파일, 원하는 칼럼(열) 선택적으로 불러와서 dataframe으로 나타내기 - usecols (0) | 2021.03.10 |
|---|---|
| [데이터분석] 엑셀 파일, 원하는 행 선택적으로 불러와서 dataframe으로 나타내기 - skiprows (0) | 2021.03.10 |
| [데이터분석] 엑셀을 데이터 프레임으로 불러올 때 Sheet 설정하는 방법 - sheet_name (0) | 2021.03.10 |
| [데이터분석] 엑셀(excel) 파일 dataframe으로 불러오기 - pd.read_excel() (0) | 2021.03.10 |
| [데이터분석] matplotlib : 파이차트(pie chart) 간단하게 만들기 (0) | 2021.03.10 |

