데이터 리뷰 : 데이터 대신 읽어드립니다!
#28 AIHUB(음성/자연어) - 공공행정문서 OCR 데이터

대부분의 공공기관이나 공기업 등에서는 1년에 몇 만 건의 공공행정문서를 처리하는데요, 눈으로 일일이 보고 처리하는 데에 많은 시간과 불필요한 인력이 낭비되고 있습니다. 따라서, 이러한 공공행정문서들을 자동으로 인식하여 처리할 수 있는 기술 및 시스템은 필요시 되고 있답니다. 하지만 공공행정문서마다 그 형태나 포맷이 제각각이고, 인쇄체뿐만 아니라 손으로 작성된 문서도 있으며, 스캔된 문서 이미지를 이용한다는 점에서 해상도도 제각각일 수 있어서 특화된 기술, 높은 정확도의 기술이 요구됩니다. 이에 대해 이를 만족시킬 수 있는 기술 중 하나는 바로 OCR이라는 것인데요, OCR(Optical Character recognition)이란 '광학적 문자 판독장치'로 종이에 인쇄된 문자에 빛을 비추어 그 반사 광선을 전기 신호로 바꾸어 컴퓨터에 입력하는 것을 말하는데요, AI가 접목된 OCR 기술은 문자가 적힌 문서 이미지에서 글자를 인식하여 텍스트로 처리해주는 기술을 말합니다.
이와 관련해서 AIHUB에서는 공공행정문서에 특화된 OCR 모델 개발을 위한 데이터셋 구축을 목적으로 '공공행정문서 OCR' 데이터를 제공하고 있습니다. 그럼 이번 데이터 리뷰기에서는 이 데이터가 어떻게 이루어져 있는지 살펴보고, 어떻게 분석 및 활용하면 좋을지 생각해보도록 하겠습니다!
공공행정문서 OCR 데이터
(1) 데이터 정보
- 제공기관 : 동양시스템즈 주식회사
- 데이터 개수 : 90만 개
- 데이터 형식 : json, jpg
- 데이터 구성 : 데이터셋, 이미지 생산연도, 카티고리, 파일명, 해상도, 어노테이션 정보, 라이선스 정보 등 18개
- 다운로드 : https://aihub.or.kr/aidata/30724
'공공행정문서 OCR' 데이터는 공공 행정 문서에 특화된 문자인식 AI 모델을 개발하기 위해 구축된 공공 행정 문서 이미지 데이터로, 생성시점이 오래되어 스캔 및 촬영 화질이 좋지 않고, 다양한 문자형태(수가, 인쇄체, 타자체 등)를 포함하는 문서에 대한 데이터로 구축되어 있답니다.
데이터 구축 과정은 아래와 같이 이루어졌는데요, 먼저 데이터를 획득한 후, 개인정보 등의 비식별화를 위해 공개 가능 문서를 선별하여 데이터를 정제하고, 라벨링 가공과 품질 검수를 거쳐 민간정보에 대한 제약사항이 발생하지 않는지 다단계 검증을 통한 비식별화 조치가 이루어졌다고 합니다!

한편, 위에 다운로드 링크로 들어가면 회원가입 또는 로그인 후 데이터를 다운받을 수 있는데요, 데이터를 다운받아서 한번 데이터가 어떻게 이루어져 있는지 살펴보도록 하겠습니다~
(2) 데이터 리뷰
공공행정문서 OCR 데이터를 다운로드 받으면, 12개의 카테고리로 분류된 공공행정문서 이미지와 라벨링 데이터가 있는 json 파일이 있는데요, 해당 공공행정문서는 경상남도 김해시의 지방자치단체 고유업무 전반에 걸쳐 생상된 공공행정문서라고 합니다. 전체 이미지는 약 90만 장이 있으며, 구축 이미지 기준 2,500만 단어 클래스별 구축되었다고 합니다.
그럼 다운로드 받은 데이터 중 '주민생활지원' 클래스로 분류된 데이터 하나를 살펴보겠습니다.


왼쪽에 있는 이미지는 해당 문서 이미지, 오른쪽은 json 형식의 라벨링 데이터입니다. 라벨링 데이터는 문서 이미지에 있는 텍스트에 대한 정보를 담고 있는데요, 상단에는 문서에 대한 정보, 그 아래로는 어노테이션에 대한 정보를 담고 있습니다. 조금 더 자세하게 알아볼까요~?
#이미지 정보

먼저, 문서 이미지 정보를 보면, 순서대로 이미지 생산기관, 이미지 생산연도, 카테고리, 높이, 너비, 파일명, 이미지 생성일자를 알 수 있습니다.
#어노테이션 정보

반면, 어노테이션 정보로는 인식된 텍스트, 텍스트타입(수가/인쇄체 등), 바운딩 박스 좌표 등을 알 수 있습니다.
위 데이터의 일부분에서는 '아름답게' 라는 텍스트가 인식되었다고 나오는데요, 앞에 문서 이미지를 보면 제일 상단에 '아름답게'라는 부분이 있는 것을 확인할 수 있습니다.
그렇다면 전체적으로 어떠한 텍스트가 인식되었는지 코드를 이용하여 출력해보겠습니다.
import json
with open('5350046-2004-0001-0392.json', 'r', encoding='UTF8') as f :
json_data = json.load(f)
datas = json_data
for i in datas['annotations'] :
print(i['annotation.text'])
위 코드는 jupyter notebook과 python을 이용하여 해당 json 파일을 열어 어노테이션 텍스트를 출력하는 코드인데요, 위 코드를 입력하고 실행하면 아래와 같이 출력됩니다.
아름답게, 시민을 김해시 수신자 수신자 참조 (경유) 제목 당면 현안사항 통보 지난 7. 22(목) 경남도 주관으로 개최한 도내 부시장·부군수 회의시 당면현안 사항을 붙임과 같이 통보하오니 업무 추진에 참고하시기 바라며 해당부서에서는 자체 세부추진계획을 수립하여 시행에 만전을 기하여 주시기 바랍니다. 붙 임 : 당면 현안사항 1부. 끝. 김 해 시 장 관인생략 수신자 의회사무국장 전과 · 사업소 ·읍면동장 전결 07 / 26 지방행정주사보 김재한 지방행정주사 구정회 주민자치과장 김선도 시행 주민자치과-5554 (2004.07.26.) 칠암도서관-2956 (2004.07.27.) 우 621-701 부원동 623 / 전화 (055)330-3093 (055)330-3099 / / 아름답게, 시민을
앞에 문서 이미지와 비교해보면 해당 텍스트가 일치하는 것을 살펴볼 수 있습니다.
한편, 어노테이션 정보에 바운딩 박스 좌표가 있었는데요, 이는 해당 텍스트를 박스쳤을 때 4개의 꼭짓점 좌표로, 시각화하면 아래와 같은 모습입니다.
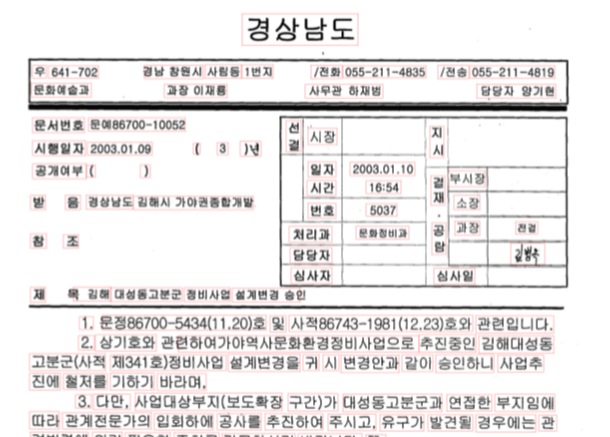
위 이미지를 보면 각 문자 단위마다 박스가 쳐진 것을 확인할 수 있습니다!
(3) 데이터 활용
그렇다면 공공행정문서 OCR 데이터를 어떻게 활용할 수 있을까요?
우선, 공공기관에서 생산된 공공행정문서는 법적 보존 연한에 따라 보존 관리되고 있따고 하는데요, 중요도가 높은 공공행정문서의 경우 보존기간이 길어서 장기간 보존을 하고 있지만 오랜 기간 보존으로 인해 원본 문서의 변질 또는 훼손의 우려가 높다고 합니다. 또한 디지털화한 이미지의 품질이 좋지 않아 기존의 상용 OCR 사용 시 인식률이 저조하다고 합니다. 따라서 해당 데이터를 이용하여 OCR 모델의 학습 데이터로 사용한다면, 문서에 대한 인식률이나 정확도를 높일 수 있지 않을까 싶습니다. 또한 각 분야별로, 형식과 형태 및 작성 형태가 제각각인 약 90만 건의 데이터가 있기 때문에 다양한 문서를 학습시키는 데에는 적절할 것 같습니다.
한편, 여러 OCR AI 모델이 있는데요, 대표적인 모델로는 테서렉트의 OCR, Easy OCR, Korea OCR 등이 있습니다. 이러한 모델들은 추가로 데이터를 학습시킬 수 있게 되어 있는데요, 공공행정문서 OCR 데이터를 추가로 학습시켜 한국 공공문서, 한국어 문자 등에 대한 학습을 시킨다면, 공공행정문서 인식에 대한 정확도를 더 높일 수 있게 됩니다.
이렇게 OCR 모델을 추가로 학습시켜 공공행정문서에 특화된 OCR 모델을 만든다면 다양하게 활용할 수 있는데요, 새로운 문서 이미지를 입력하면 원하는 내용의 데이터가 데이터베이스에 자동으로 입력된다거나, 공공행정문서 자동 검색을 통한 행정업무 활용에 도움을 줄 수 있지 않을까 싶습니다. 또한 비슷한 문서를 찾아주는 공공행정문서 공개서비스 등 다양하게 활용될 수 있을 것 같습니다!
# AIHUB
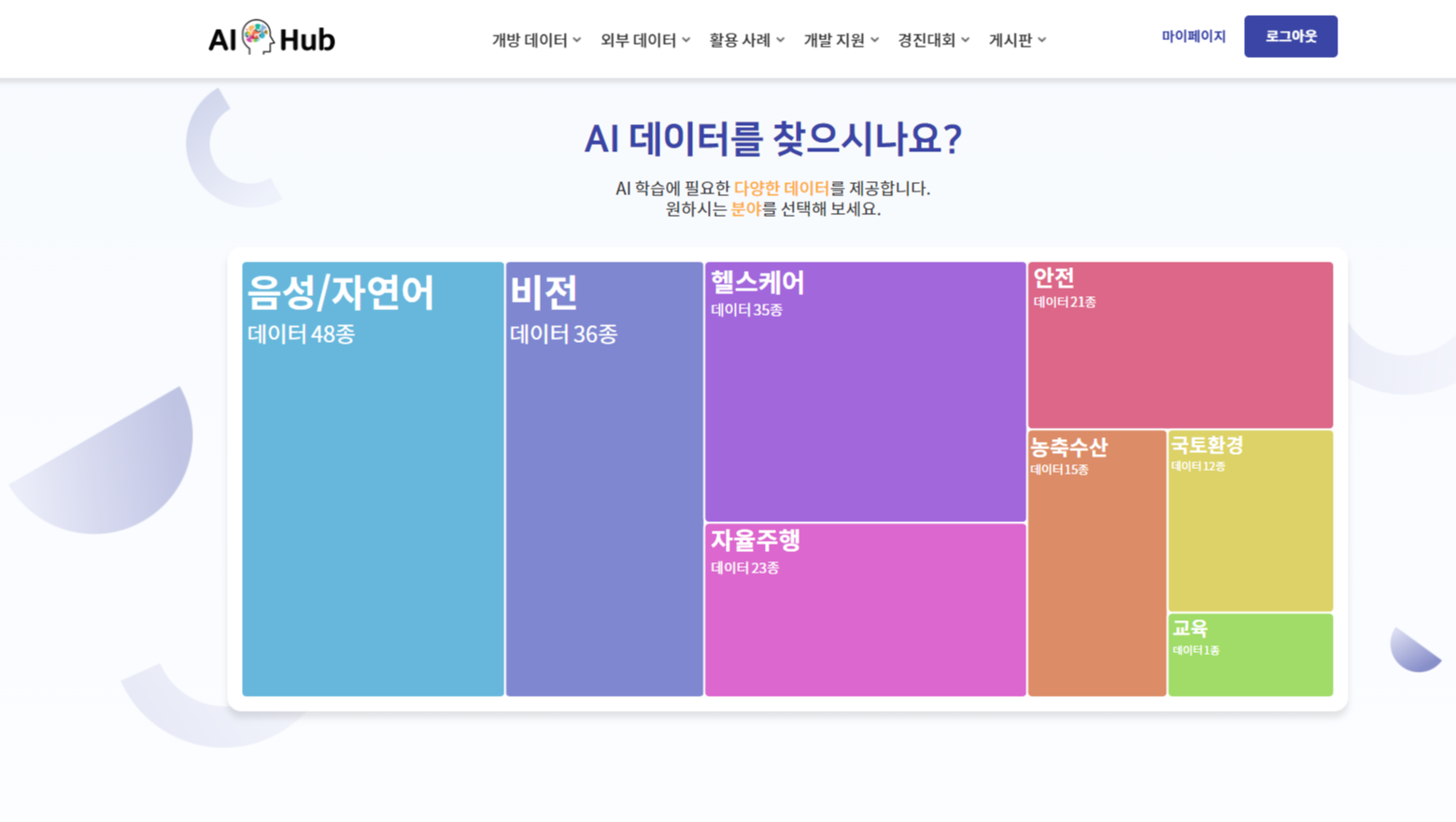
오늘 리뷰한 '공공행정문서 OCR' 데이터는 <AIHUB(AI 허브)>에서 다운로드 받은 '음성/자연어' 카테고리의 데이터로, AI 허브는 AI 기술 및 제품, 서비스 개발에 필요한 AI 인프라(AI데이터, AISWAPI, 컴퓨팅 자원)를 지원함으로써 누구나 활용하고 참여하는 AI통합 플랫폼입니다! 따라서 사용자를 위해 개발 및 활용을 위한 인프라 서비스와 AI 활성화를 위한 서비스를 제공하고 있는 것인데요, 현재 위와 같이 음성/자연어, 비전, 헬스케어, 자율주행 등 다양한 카테고리에 걸친 데이터들을 제공하고 있답니다.
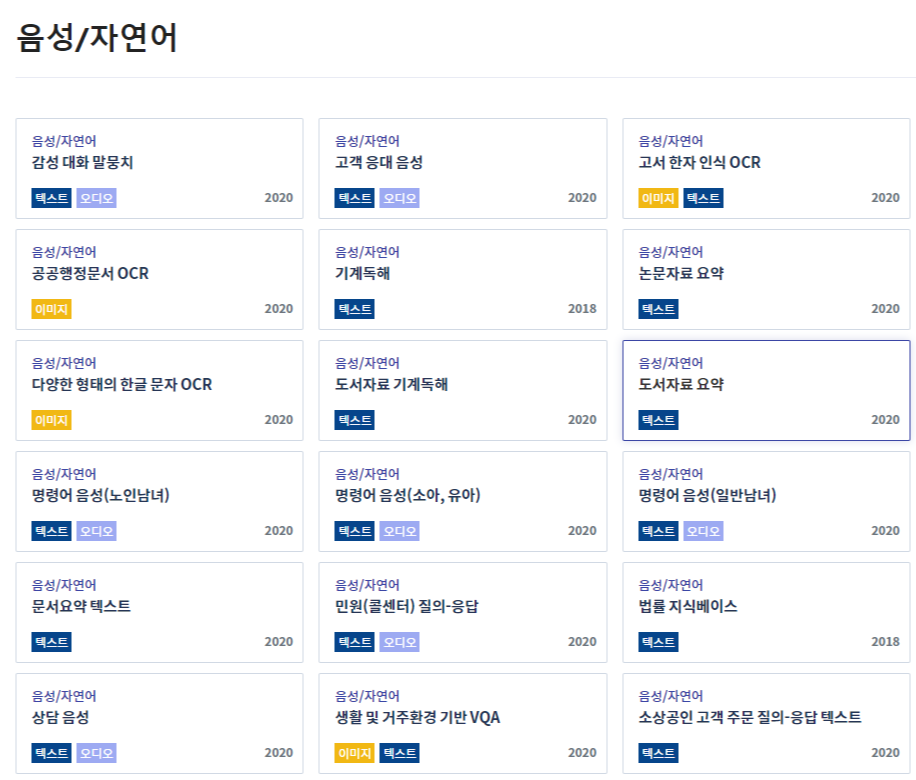
한편, 오늘 살펴본 데이터는 '음성/자연어' 카테고리에 있는 데이터였는데요, 음성/자연어 카테고리는 음성 파일로 이루어진 데이터나 기계독해 등 텍스트와 관련된 데이터를 제공하는 카테고리입니다. 특히 다른 빅데이터 플랫폼에서는 찾아보기 힘든 데이터들이 제공되고 있고, 한국어, 한국인 음성, 한글로 이루어진 텍스트 등 서양보다는 우리나라에 맞춰져 있는 데이터들이 있기 때문에 상당히 활용하기에 적합한 데이터이기도 합니다.
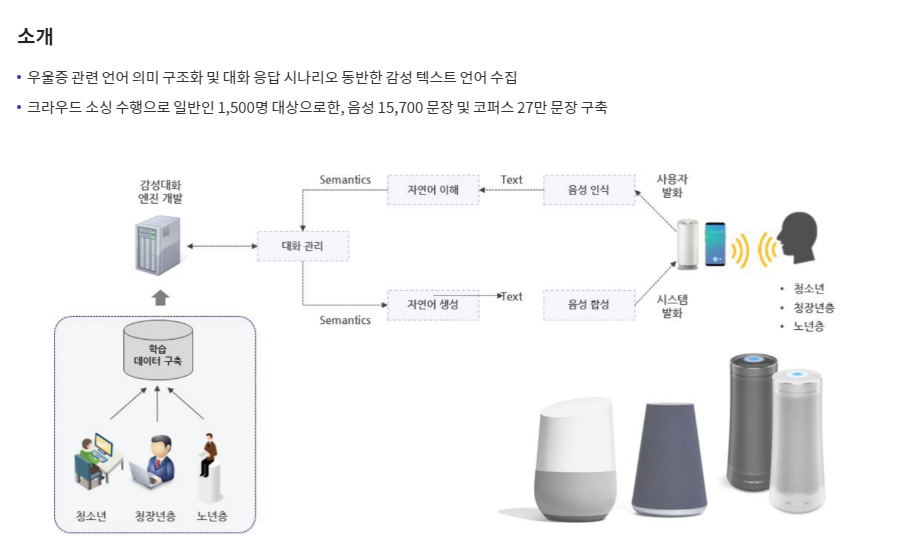
또한 각 데이터 다운로드 페이지에 들어가면 위와 같이 데이터의 구축내용과 필요성, 데이터 구조, 활용예시 등의 정보를 파악할 수 있기 때문에 데이터를 다운로드하기 전에 어떠한 형태로 이루어져 있는지 살펴볼 수 있답니다.
이렇게 오늘 데이터 리뷰기에서는 AIHUB의 '공공행정문서 OCR' 데이터를 리뷰해보았는데요, 다음 리뷰기에서는 다른 카테고리의 데이터를 리뷰해보도록 하겠습니다. 이전 데이터 리뷰기에서는 소방, 사회 범죄, 해양수산, 헬스케어, 농수산물 등 여러 플랫폼에서 제공하는 데이터 리뷰기가 있으니, 관심이 있으신 분들은 참조하시기 바랍니다! 그럼 다음 리뷰기에서 만나요! :D

'BLOG > 데이터 리뷰기' 카테고리의 다른 글
| [데이터 리뷰] AIHUB(국토환경) - 생활 폐기물 이미지 데이터 (0) | 2021.09.18 |
|---|---|
| [데이터 리뷰] AIHUB(국토환경) - 관광 지식베이스 데이터 (0) | 2021.09.17 |
| [데이터 리뷰] AIHUB(음성/자연어) - 한국어 SNS 대화 데이터 (0) | 2021.09.15 |
| [데이터 리뷰] AIHUB(음성/자연어) - 논문자료 요약 데이터 (0) | 2021.09.14 |
| [데이터 리뷰] AIHUB(음성/자연어) - 한국어 대화 요약 데이터 (0) | 2021.09.13 |



