이미지를 크롤링해서 저장하고 싶다면 urlib 이라는 라이브러리를 통해 이미지를 저장할 수 있습니다.
한편, 이미지는 주로 'src' 태그에 'https://링크~.jpg' 이런 식으로 텍스트로 되어 있는데요, 이 텍스트를 가져온 다음, urlib를 이용하여 폴더에 저장하면 된답니다.
그렇다면, 예시로, 네이버 웹툰 홈페이지에서 아래 이미지와 같이 웹툰의 섬네일을 저장하는 방법에 대해서 살펴보겠습니다.

1. 월요웹툰 페이지 본문 가져오기
이미지를 저장하기 앞서, 먼저 월요웹툰 페이지를 열고, 해당 페이지의 본문을 가져오는 코드를 작성하도록 하겠습니다.
from bs4 import BeautifulSoup
import requests
import urllib.request
import urllib
url = "https://comic.naver.com/webtoon/weekdayList.nhn?"
params = {
'week' : 'mon' }
resp = requests.get(url,params)
soup = BeautifulSoup(resp.content, 'lxml')
위 코드를 입력하고 실행하면 soup 라는 변수에 해당 본문이 출력됩니다.
2. 이미지 url 저장하기
위에서 언급했듯이, 이미지는 url 형식의 텍스트로 입력되어 있는데요, f12를 눌러 해당 링크를 찾아보도록 하겠습니다.
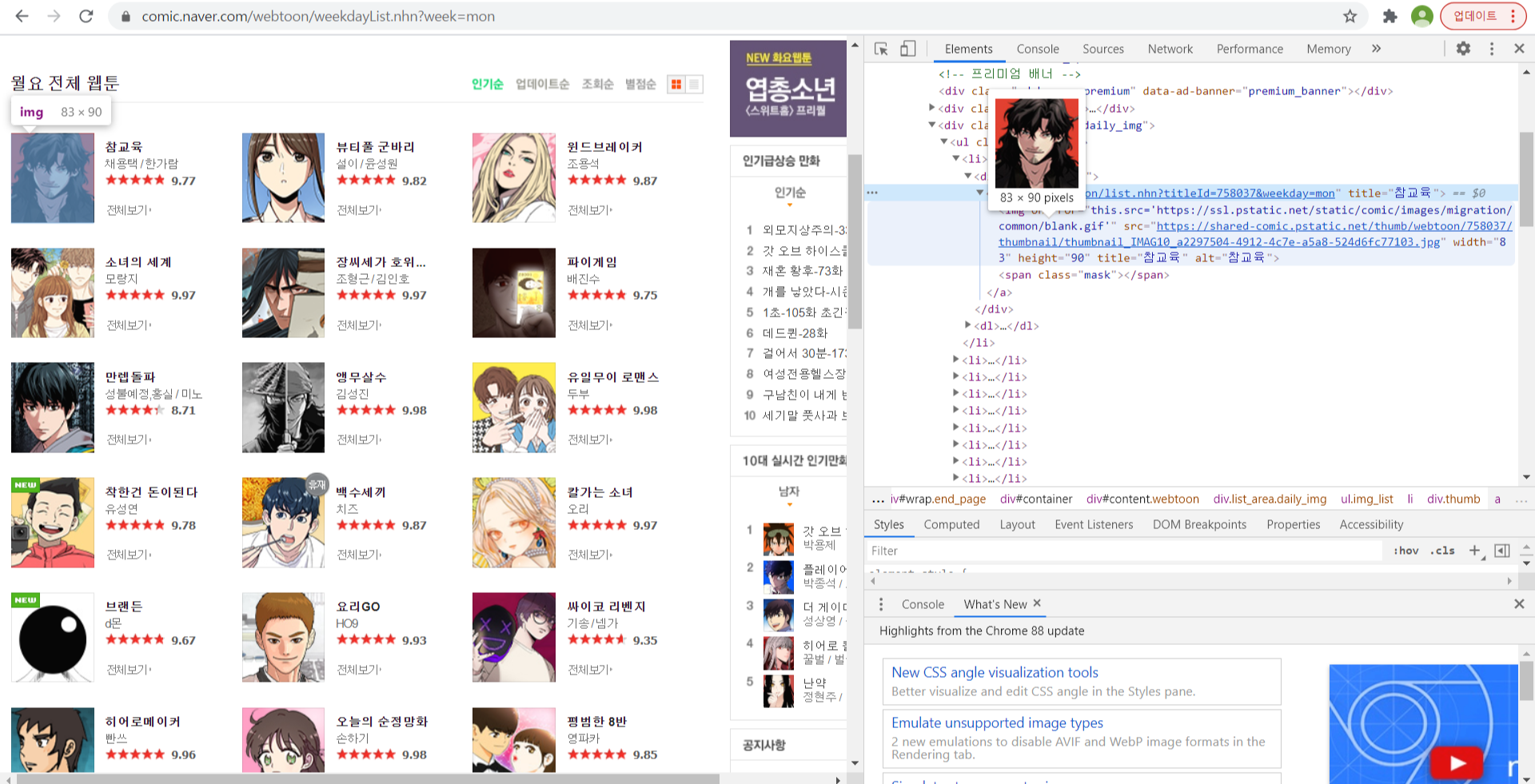
오른쪽에 이미지가 있는 영역에 태그부분을 보면, 'img' 태그에 'src' 속성에 이미지 링크가 있는 것을 알 수 있습니다.
이제 모든 썸네일에 대한 링크를 리스트에 저장하는 코드를 작성해 보도록 하겠습니다.
img_src = soup.find('ul','img_list').find_all('img')
img_list = []
for j in img_src :
img_src1 = j['src']
img_list.append(img_src1)
첫 번째 줄은 'ul' 태그, 'img_list'라는 클래스명을 가진 element에서 모든 'img' 태그에 있는 링크를 저장하는 코드입니다.
그리고, for문을 사용하여 'src' 속성에 담긴 링크만 따로 새로운 리스트에 저장하도록 코드를 작성해주었습니다.
위 코드를 실행한 뒤 img_list 리스트를 출력하면 링크만 담긴 데이터들을 볼 수 있습니다.
3. 폴더에 저장하기
url을 모두 크롤링했다면, 이제 urlib 라이브러리를 이용해서 저장해야 하는데요, 아래와 같이 코드를 작성하면 현재 폴더에 해당 섬네일이 저장된답니다.
file_no = 0
for j in range(0,len(img_list)) :
try :
urllib.request.urlretrieve(img_list[j],str(file_no)+'.jpg')
except :
continue
file_no += 1
time.sleep(0.5)
모든 코드를 실행하고 나면, 아래와 같이 폴더에 저장된 것을 확인할 수 있습니다.

'BLOG > 웹크롤링' 카테고리의 다른 글
| [웹크롤링] 텍스트 입력 시 글자가 생략되거나 오타가 나는 문제, 해결 방법은? (0) | 2021.03.19 |
|---|---|
| [웹크롤링] 크롤링 수행 시간 측정하기 - time (0) | 2021.03.19 |
| [웹크롤링] 네이버 - 연관 검색어 크롤링하기 (requests 사용) (0) | 2021.03.18 |
| [웹크롤링] 네이버 - 원하는 검색어가 입력된 페이지 열기 (0) | 2021.03.18 |
| [웹크롤링] 크롤링한 데이터 메모장(텍스트 파일)에 저장하는 방법 (0) | 2021.03.18 |

